
메타태그와 api를 사용해서 유투브 동영상 정보 끌어오기
17 Apr 2022 | backend api목적
사용자에게 입력받은 여러 형태의 유투브 비디오 링크로 썸네일, 길이, 비디오 크기, 채널이름, 제목, 설명을 끌어와서 사용한다.
1. 입력받은 링크에서 키를 추출한다.
import re
import json
from urllib.request import urlopen
from urllib.parse import urlparse, parse_qs
from contextlib import suppress
from configuration import yt_api_key
def get_yt_id(url, ignore_playlist=False):
# Examples:
# - http://youtu.be/SA2iWivDJiE
# - http://www.youtube.com/watch?v=_oPAwA_Udwc&feature=feedu
# - http://www.youtube.com/embed/SA2iWivDJiE
# - http://www.youtube.com/v/SA2iWivDJiE?version=3&hl=en_US
query = urlparse(url)
if query.hostname == 'youtu.be': return query.path[1:]
if query.hostname in {'www.youtube.com', 'youtube.com'}:
if not ignore_playlist:
# use case: get playlist id not current video in playlist
with suppress(KeyError):
return parse_qs(query.query)['list'][0]
if query.path[:7] == '/shorts': return query.path.split('/')[2]
if query.path == '/watch': return parse_qs(query.query)['v'][0]
if query.path[:7] == '/watch/': return query.path.split('/')[1]
if query.path[:7] == '/embed/': return query.path.split('/')[2]
if query.path[:3] == '/v/': return query.path.split('/')[2]
# returns None for invalid YouTube url
def get_yt_duration(url):
video_id = get_yt_id(url)
video_url = "https://www.googleapis.com/youtube/v3/videos?id=" + video_id + "&key=" + yt_api_key + "&part=contentDetails&part=snippet"
response_video = urlopen(video_url).read()
data_video = json.loads(response_video)
channel = data_video['items'][0]['snippet']['channelTitle']
duration = data_video['items'][0]['contentDetails']['duration']
reg_dt = data_video['items'][0]['snippet']['publishedAt']
thumbnail = data_video['items'][0]['snippet']['thumbnails']['medium']['url']
match = re.match('PT(\d+H)?(\d+M)?(\d+S)?', duration).groups()
hours = _js_parseInt(match[0]) if match[0] else 0
minutes = _js_parseInt(match[1]) if match[1] else 0
seconds = _js_parseInt(match[2]) if match[2] else 0
if hours:
if len(str(minutes)) == 1:
minutes = '0' + str(minutes)
duration = str(hours) + ':' + str(minutes) + ':' + str(seconds)
else:
if len(str(seconds)) == 1:
seconds = '0' + str(seconds)
duration = str(minutes) + ':' + str(seconds)
return {'channel': channel, 'duration': duration, 'reg_dt': reg_dt, 'thumbnail': thumbnail}
# js-like parseInt
def _js_parseInt(string):
return int(''.join([x for x in string if x.isdigit()]))
if __name__ == '__main__':
#추출하고 싶은 링크를 입력하고 파일을 돌린다.
link = 'https://youtu.be/NSAzhdHeHK4'
print(get_yt_id(link))
print(get_yt_duration(link))
키 추출하는 부분 출처 : https://stackoverflow.com/questions/4356538/how-can-i-extract-video-id-from-youtubes-link-in-python
2. 키를 이용해서 api를 치고 영상길이와 채널이름을 추출한다.
def get_yt_duration(url):
results = {}
video_id = get_yt_id(url)
video_url = "https://www.googleapis.com/youtube/v3/videos?id=" + video_id + "&key=" + yt_api_key + "&part=contentDetails&part=snippet"
response_video = urlopen(video_url).read()
data_video = json.loads(response_video)
channel = data_video['items'][0]['snippet']['channelTitle']
duration = data_video['items'][0]['contentDetails']['duration']
match = re.match('PT(\d+H)?(\d+M)?(\d+S)?', duration).groups()
hours = _js_parseInt(match[0]) if match[0] else 0
minutes = _js_parseInt(match[1]) if match[1] else 0
seconds = _js_parseInt(match[2]) if match[2] else 0
if hours:
if len(str(minutes)) == 1:
minutes = '0' + str(minutes)
duration = str(hours)+':'+str(minutes)+':'+str(seconds)
else:
if len(str(seconds)) == 1:
seconds = '0' + str(seconds)
duration = str(minutes) + ':' + str(seconds)
return {'channel' : channel, 'duration' : duration}
# js-like parseInt
def _js_parseInt(string):
return int(''.join([x for x in string if x.isdigit()]))
참조 : https://stackoverflow.com/questions/16742381/how-to-convert-youtube-api-duration-to-seconds
3. soup으로 메타태그에서 썸네일, 제목, 설명, 태그, 비디오 크기 가져온다.
@ns.route("/videolink")
@ns.doc(responses={200: 'Success', 300: 'Redirected', 400: 'Invalid Argument', 500: 'Mapping Key Error'})
@ns.expect(video_model)
class ParsingVideoUpload(Resource):
@jwt_required
def post(self):
"""
동영상 링크 입력
:return:
"""
conn = g.db
args = request.json
url = args['video_link']
try:
# 링크도 아닌 문자열같은게 들어오지는 않았는지 검사한다.
assert 'youtu' in url, '영상포스팅에는 유튜브 링크만 첨부 가능합니다'
# 유효한 링크인지 연결을 검사하고
res = urlopen(url)
print('****res.status :', res.status)
# 헤더를 넣어주면 크롤링으로 인식하지 않아서 403에러가 나지 않는다.
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get(url, headers=headers, timeout=3)
soup = BeautifulSoup(data.text, 'html.parser')
#soup으로 사이트 이름 메타태그를 뽑아서 유튜브인지 확인하고
if soup.select_one('meta[property="og:site_name"]')['content'] == "YouTube":
# 주소에서 아이디 추출
youtube_id = get_yt_id(url)
# api로 영상길이와 채널이름 추출
youtube_data = get_yt_duration(url)
video_duration = youtube_data['duration']
channel_title = youtube_data['channel']
video_thumbnail = 'https://img.youtube.com/vi/'+ youtube_id +'/mqdefault.jpg'
video_tags = soup.select_one('meta[name="keywords"]')['content']
video_title = soup.select_one('meta[property="og:title"]')['content']
video_desc = soup.select_one('meta[property="og:description"]')['content']
video_width = soup.select_one('meta[property="og:video:width"]')['content']
video_height = soup.select_one('meta[property="og:video:height"]')['content']
#썸네일 추출 안 되었으면 고정값 삽입
if not video_thumbnail:
print("동영상에서 썸네일 이미지를 불러올 수 없습니다.")
video_thumbnail = 'https://cloudfront.alpha-bridge.kr/dev/image/board/youtube_thumbnail_default.png'
data = {
'youtube_id': youtube_id,
'channel' : channel_title,
'video_duration': video_duration,
'thumbnail_img': video_thumbnail,
'video_tags': video_tags,
'video_title': video_title,
'video_desc': video_desc,
'video_width': video_width,
'video_height': video_height
}
return {'result': 'success', 'data': data}
except HTTPError as e:
# 유효하지 않으면 에러 출력
err = e.read()
code = e.getcode()
print('****code :', code) ## 404
return {'result': 'failed', 'err_code' : code}
google youtube api quota(할당량) 관련
영상포스팅 작성시 입력, 발행, 수정할 때에 api를 요청하므로 글 1개 작성할 때 2번의 api를 요청하게 되고 할당량은 10정도 사용하는 것 같다.(사진 및 링크 참조) 현재 할당량은 하루에 만건이므로 1000건 정도의 생성 및 수정을 감당할 수 있다. 할당량은 추가로 요청하면 되는데 5주정도 걸린다고 한다.
참고: https://developers.google.com/youtube/v3/determine_quota_cost
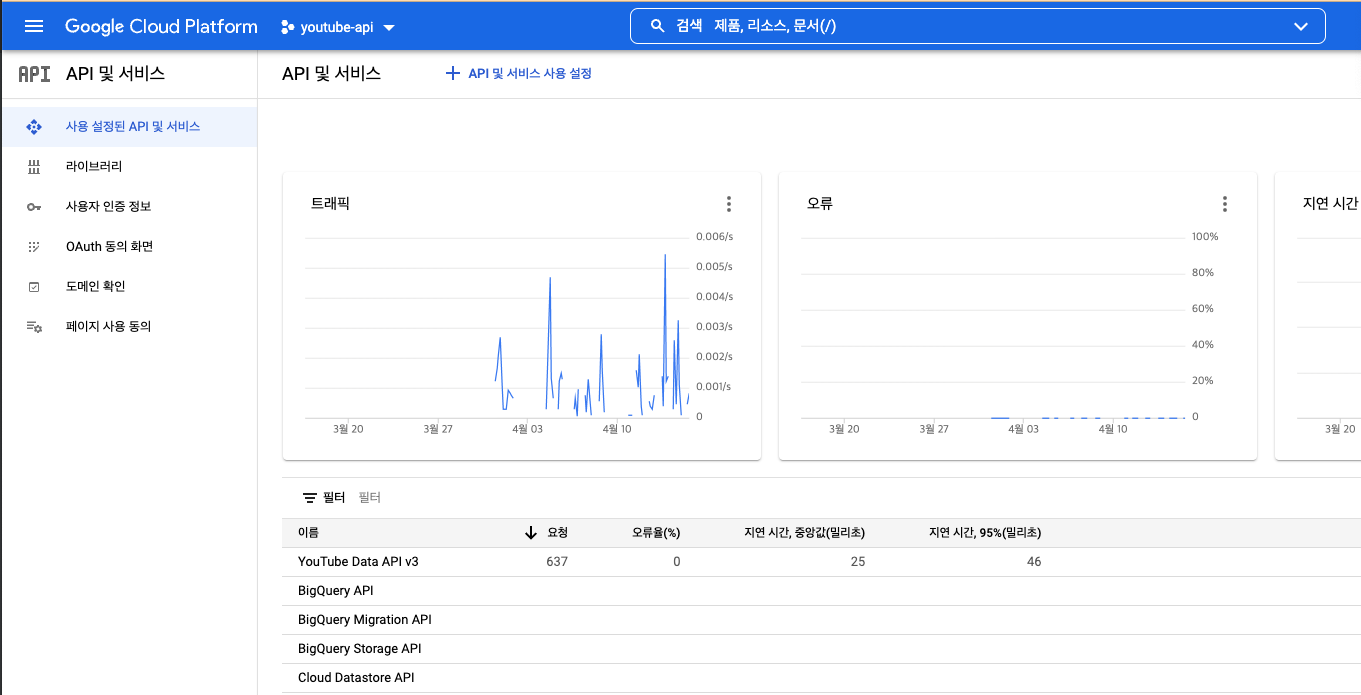
유투브 api 키등록 관련 참고 : https://datadoctorblog.com/2021/09/12/etc-google-cloud-platform-youtube/ 유투브 api json 구조 관련 공식 문서 : https://developers.google.com/youtube/v3/docs/videos