온보딩이 종료되고 취준을 다시 시작했는데 이번에는 신중하게 붙을 가능성이 있는 곳 위주로 지원했다. 트릿지에서는 코딩테스트를 통과했는데 컬처핏에서 떨어져서 약간 의아했고 크립토파라다이스의 코딩테스트는 너무 어려워서 풀지 못했다. 브랜디 코딩테스트는 3개 중에 1개만 맞았다.
전에 붙었던 회사에서 또 전화가 왔는데 1달만에 개발 전체 담당자분이 바뀌었어서 안 가길 잘했다는 생각이 들었다. 잡플래닛 평점이 2점대인 회사에 면접을 보러갔었는데 회사는 괜찮아보였지만 개발이 메인이 아니고 운영 직군의 입김이 센 것 같았다.
원티드 4개, 링크드인 1개, 로켓펀치에 30개 정도를 넣었고 면접을 6개, 코딩테스트를 3개 정도 보았다.
인성면접과 컬쳐핏면접을 몇번 보게되었는데 주로 개발자로서의 장/단점과 프로젝트를 하면서 어려웠던 점과 그 이유를 많이 물어보아서 정리해보았다.
개발자로서의 장점과 단점
장점
항상 지식을 공유하고 좋은 커뮤니케이션을 통해서 문제 해결을 위해 함께 힘쓴다.
프론트엔드 개발에 대한 지식도 겸비하고 있어 협업시 소통을 원활하게 할 수 있다. (예리님께서 이건 단점으로 보일 수도 있다고 하셨다.)
어려운 기능을 구현하는 와중에도 끈기를 가지고 긍정적인 마인드를 가졌다. 모르는 부분에 대해서 질문하는 것을 두려워하지 않으며 이해도도 높아 학습의 속도가 빠르다.적극적인 의사표시로 자신의 의견을 전달할 줄 알고, 개발 의외에 부분에서도 인간적으로 상대방을 챙기고 돕는다.
단점
스페셜리스트보다는 제네럴리스트인 성격이라 에너지가 분산되는 경향이 있다. 예를 들어서 독일어(B1), 스페인어(IM3), 일본어를 조금씩 하는데 이 시간과 노력을 전부 영어에 쏟았다면 영어로 더 글을 잘 쓸 수 있었을거라고 생각한다. 같은 맥락으로 웹디자이너로 일하지 않고 바로 백엔드 개발 공부를 시작했었더라면 지금 더 잘 할 수 있었을 것 같지만 이제라도 다른 것 외에 백엔드 개발만 생각하려고 한다.
실력이 부족해서 자신감이 부족한 경향이 있다. 공부를 많이 해서 실력이 늘면 나아지지 않을까 생각한다.
프로젝트 하면서 어려웠던 점
1차 프로젝트때 PM을 맡았는데 잘 진행을 하다가 어떤 기능이 구현이 안 되서(회원, 비회원 토큰관련) 여유가 없어서 팀 전체를 잘 챙기지 못했는데 다행히 정말 좋은 팀원분들을 만나게되어서 다른 팀원분들께서 함께 챙겨주셔서 잘 마무리했다.
2차 프로젝트때는 맡은 기능 + AWS 구현에 집중했는데 새로운 인프라 관련 기능을 구현하느라 즐거워서 지하철에서도 코딩을 할만큼 열심히 했다. 팀분위기는 아주 좋았고 원하는 기능도 모두 잘 구현했지만 AWS 객체를 삭제하는 부분이 원활하지 못했어서 끝나고 인턴을 하면서 공부하고 적용했다.
인턴(5주, 1프로젝트)을 할 때는 팀 분위기가 굉장히 좋았고 채용 관리자페이지를 마지막까지 잘 구현했다. API정리를 막판에 하다가 시간에 쫓기긴했는데 결국 원하는 기능은 전부 구현했고 기획대로 잘 돌아가고 팀원들과도 돈독하고 좋았다.
온보딩때는 내가 제일 못하는 팀원이었는데 위코드와 다르게 서로 모르는 상태로 어려운 프로젝트(5주, 7개 프로젝트)를 타이트한 스케줄로 들어가서 이틀에 한 개씩 프로젝트를 하면서 매번 밤을 새고 압박, 좌절, 체력의 한계를 느끼게되었다. 실력이 부족하면 개발자로 함께 일할 수 없겠다는 생각이
들어서 조금 현타가 왔었던 것 같다. 추후 온보딩 프로젝트의 난이도가 굉장히 높은 것이었다는 이야기를 듣고 조금 안심이 되었다.
온보딩 후 동료 평가 내용
긍정적 동료되기
항상 긍정적인 성격을 가지고 계시고, 어느 상황에서나 침착함을 잃지 않으십니다. 덕분에 조금 편한 마음으로 프로젝트를 진행했습니다.
모여서 과제를 할 때 답답한 분위기를 환기시켜주셔서 감사했습니다.
도전하고 주도하기
모르는 기술인 DRF를 바쁜일정에도 습득 하시려고 노력을 하셨습니다. 미리 결과를 단정짓지 않고 도전하시는 부분들을 많이 가지고 계셔서 저에게 많이 도전이 되었습니다. 팀의 리더가 있고 선후배 개발자가 아닌 같은 레벨에 있는 팀원들끼리 프로젝트를 하는데 있어서 팀원들의 의견을 잘 들어주시고 배려와 수용하시는 면이 많으셨습니다. 조금만 더 본인의 의견이나 목소리를 내어 주시면 완벽할거 같습니다. 밤까지 함께 과제를 수행하며 끝까지 해결할 수 있어서 좋았습니다.
린하게 해결하기
직접 맡으신 부분을 바로 수행하시는 모습이 인상적 이었습니다.
구현 -> 테스트 단계별로 구현하셨고, 테스트 구현시 실패를 하게되면 원인을 찾아서 코드를 수정하셨습니다.
전체적인 흐름을 이해한 뒤 프로젝트를 진행해주시고, 본인이 할 수 있는 범위에 대해서 먼저 공유해주셔서 좋았습니다.
데이터로 소통하기
여러 사이트와 문서를 참고하여 기능 구현하시는 점이 인상깊었습니다. 다양한 데이터에 대한 정보를 공유하며 문제해결에 힘써주셨습니다.
일례로 url설계나 db설계를 외부 소스에서 참고해주시는 면이 좋았습니다. 과제마다 접해보는 기술이 다르고 새로웠기 때문에, 관련 자료를 찾아서 공유해주셨습니다.
집단지성 활용하기
모르시거나 의문의 드는점들을 계속 공유해주셔서 구현하시는 부분을 어느정도 하신건지 잘 알 수 있었습니다. 공부할 수 있는 자료나 새롭게 알게 된 부분들은 팀 채널에 먼저 공유해주시며, 팀이 좋은 방향으로 나아갈 수 있게끔 해주셨습니다. 여러 방안에 대해 피드백 주시고 함께 얘기하며 구현을 할 수 있었던 것 같습니다.팀원 전체의 의견을 잘 수용해주셨습니다.
품질과 기한 지키기
함께 새로운 약속을 할때 빠짐없이 잘 참여해주셨습니다.
상황에 따라 구현의 순서나 진행 순서를 변경하여 효율적으로 진행할 수 있었던 것 같습니다.
동료가 앞으로 더 성장하기 위해 노력하면 좋을 부분이 있다면 알려주세요.
팀원들의 이야기를 잘 들어주시는 만큼 본인의 의견도 많이많이 이야기해주시면 더욱 좋을것 같습니다.!
백엔드 부분을 배우신지 얼마 되지 않으셨는데 다양한 기능을 구현하시는 것을 보며 대단하다고 생각했습니다.
이번에 프로젝트를 진행하시면서 접해보신 기술들(Docker, DRF)을 연습하셔서 어느정도 할 수 있을 정도로 익히시면 좋을 것 같습니다.
개발실력도 있으시고, 문제를 풀어가는 힘도 가지고 계신데 자신감이 없으신 것 같아서 조금 속상했습니다. 자신감만 가지시면 분명히 좋은 개발자가 되실 거라고 확신합니다. 같이 프로젝트를 하게 되어 좋았습니다.
동료에게 특별히 응원/ 칭찬할 말이 있다면 알려주세요.
이전에 경력과 부트캠프 경험으로 봤을때는 더 퍼포먼스를 내실 수 있으실것 같은데, 먼가 환경이 잘 안맞아서 상대적으로 퍼포먼스가 안 나신것 처럼 보였습니다. 하지만 앞에서 말했듯이 이전 경험이 충분하므로, 시간과 여건만 된다면 퍼포먼스를 내실것으로 생각됩니다.
고생많으셨습니다!
루나님이 계셔서 프리온보딩 기간이 너무 좋았고, 의지가 되었습니다.
그리고 공부자료를 계속 공유해주시는 모습들이 너무 인상적이었고 감사했습니다.


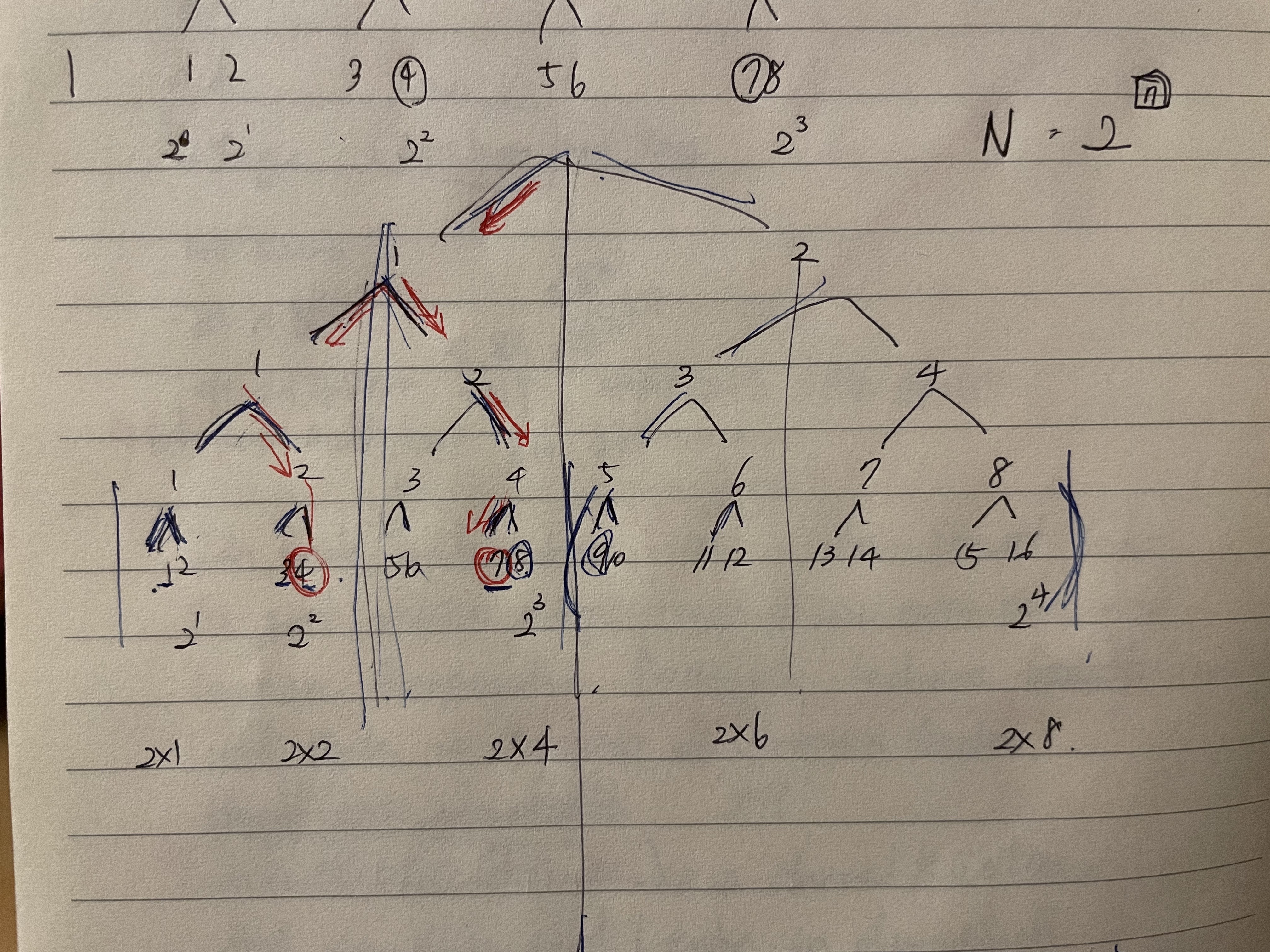 무슨 규칙이 있을까싶어서 그림을 그려보았다. 사실 이 때 깨달았어야 했다, 숫자가 계속 반띵되다가 같은 숫자가 되면 만나게 된다는 것을…
무슨 규칙이 있을까싶어서 그림을 그려보았다. 사실 이 때 깨달았어야 했다, 숫자가 계속 반띵되다가 같은 숫자가 되면 만나게 된다는 것을… ‘두 수가 8보다 작은 경우에는 3라운드(2의3승)안에서 만날 수 있지만 9부터 16까지의 수가 포함되어있는 경우에는 4라운드(2의4승)까지 가야 1부터 8사이의 참가자를 만날 수 있구나!’ 라고 생각해서 둘 중 큰 수를 루트한 값의 정수 부분이 답이라고 생각하고 아래와 같이 코드를 작성했는데 3개정도만 맞고 다 틀렸다.
‘두 수가 8보다 작은 경우에는 3라운드(2의3승)안에서 만날 수 있지만 9부터 16까지의 수가 포함되어있는 경우에는 4라운드(2의4승)까지 가야 1부터 8사이의 참가자를 만날 수 있구나!’ 라고 생각해서 둘 중 큰 수를 루트한 값의 정수 부분이 답이라고 생각하고 아래와 같이 코드를 작성했는데 3개정도만 맞고 다 틀렸다.