파이썬 - 진수 변환 함수
21 Dec 2021 | 기초 TIL진수를 변환하는게 코딩테스트에서 나와서 진수변환함수를 작성하고 인터넷에 있는 풀이들을 살펴보았다.
1번은 코딩테스트를 위해서 10진수를 N진수로, N진수를 10진수로 변환하라는 조건을 위해서 만든 클래스고
2번은 유투브에서 찾은 10진수를 N진수로 바꾸는 함수이다.
3번은 검색하다가 나온 N진수에서 N진수로 만드는 함수이다.
4번은 1번의 클래스 안의 함수를 사용해서 내가 만든 N진수에서 N진수로 만드는 함수이다.
1번 : 10진수를 N진수로, N진수를 10진수로 변환하는 클래스
class Transformer(object):
#10진수로 변환할 경우 숫자들의 리스트
#This Transformaer class takes list of numbers that are being used in certain digit(진법) and hand it over to initializing method.
decimal_digits = "0123456789"
#For example, decimal digit takes 0 to 9, Binary digit takes 0 and 1.
#digits는 n진수의 숫자리스트
def __init__(self, digits):
self.digits = digits
#바꾸고자하는 십진수 수가 i에 들어가고 i값과 십진수 숫자리스트, 바꾸고자하는 진수의 숫자리스트를 반환한다.
#This question is about converting digit from and to decimal digits so we make two methods.
def from_decimal(self, i):
return self._convert(i, self.decimal_digits, self.digits)
#바꾸고자하는 n진수 수가 s에 들어가고 s값과 바꾸고자하는 진수의 숫자리스트, 십진수 숫자리스트를 반환한다.
#Order of decimal digits and digits matters since we are going to use convert method for both actions.
def to_decimal(self, s):
return int(self._convert(s, self.digits, self.decimal_digits))
#convert method takes number that we'd likt to change, which digit we are going to change from and to.
def _convert(self, number, fromdigits, todigits):
# 입력받은 숫자, 바꾸기 전 진수의 숫자리스트, 바꾼 뒤의 진수의 숫자리스트를 받는다. 예(555,BASE10,BASE2)
# 숫자리스트의 길이에 따라 어떤 진수로 바뀔지 정해진다.
# length of these parameters decides which digits we're going to convert.
fromdigits_len, todigits_len = len(fromdigits), len(todigits)
# 해당 진수의 숫자리스트의 길이를 저장한다. 예(BASE10은 10진수, '0123456789' 이므로 10개)
number = str(number)
number_len = len(number)
# 입력받은 숫자의 길이도 저장한다
tmp_dec=0
# 숫자의 갯수만큼 지수를 곱해서 더하여 십진수로 변환한 값을 저장한다.
# 예: 100(2진수)이면 (2의2승 * 1) + (2의1승 * 0) + (2의0승 * 0)
# Here we change all number into decimal digits.
for idx, n in enumerate(number):
# 예를 들어 십진수 1234이면 idx는 0,1,2,3 n은 1,2,3,4
print('idx :', idx)
print('n : ', n)
# By using base, exponent and digit of the number.
tmp = fromdigits_len ** (number_len-idx-1) * fromdigits.index(n)
#fromdigits_len(밑)이 십진수일 때 10이고 number_len-idx-1(지수)이 1234일때 각 3210으로 10의 지수
#fromdigits.index(n)은 1,2,3,4로 '012..89'숫자리스트에서 n번째 숫자
print('number_len-idx-1 :', number_len-idx-1)
print('fromdigits.index(n):', fromdigits.index(n))
#tmp에 각 자릿수를 십진수로 계산한 값을 더한다
tmp_dec += tmp
result=''
while tmp_dec > 0:
# 몫과 나머지를 구하는 파이썬의 내장함수 divmod사용
# And from here we change it back to N base by dividing and saving remainders.
tmp_dec, mod = divmod(tmp_dec, todigits_len)
# 10진수로된 tmp_dec를 바꾸자하는 진수의 숫자리스트길이로 나누어서
result += str(todigits[mod])
# 나온 나머지들을 반대로 정렬
return result[::-1]
BASE2 = Transformer("01")
BASE10 = Transformer("0123456789")
BASE16 = Transformer("0123456789ABCDEF")
BASE20 = Transformer("0123456789abcdefghij")
BASE62 = Transformer("ABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789abcdefghijklmnopqrstuvwxyz")
print(BASE20.from_decimal('1234'))
# print(BASE2.to_decimal('1000101011'))
2번 : 10진수를 N진수로 바꾸는 함수
출처 - https://www.youtube.com/watch?v=s3mxIcr7fOQ
from math import log
#10진수에서 원하는 진수로 바꾸기(바꿀 숫자, 바꿀 숫자의 진수)
def convertFromBase10(num, base):
#변경할 숫자의 리스트
numToChar = {i : "0123456789ABCDEF"[i] for i in range(16)}
#가장 큰 지수를 power에 저장
power = int(log(num, base))
converted = ""
#power숫자부터 0까지 거꾸로 돌리기
for pow in range(power, -1, -1):
# 진수의 가장 큰 지수(예 7의3승)로 주어진 숫자를 나누어서 몫을 converted에 더하고
converted += numToChar[num // (base**pow)]
# 나머지를 다시 숫자의 자리에 넣음
num %= base**pow
return converted
print(convertFromBase10(429,7))
#1152
3번 : N진수에서 N진수로 만드는 함수
출처 - https://code.activestate.com/recipes/111286/
BASE2 = "01"
BASE10 = "0123456789"
BASE16 = "0123456789ABCDEF"
BASE62 = "ABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789abcdefghijklmnopqrstuvwxyz"
def baseconvert(number,fromdigits,todigits):
#converts a "number" between two bases of arbitrary digits
# The input number is assumed to be a string of digits from the
# fromdigits string (which is in order of smallest to largest
# digit). The return value is a string of elements from todigits
# (ordered in the same way). The input and output bases are
# determined from the lengths of the digit strings. Negative
# signs are passed through.
# decimal to binary
# >>> baseconvert(555,BASE10,BASE2)
# '1000101011'
# binary to decimal
# >>> baseconvert('1000101011',BASE2,BASE10)
# '555'
# integer interpreted as binary and converted to decimal (!)
# >>> baseconvert(1000101011,BASE2,BASE10)
# '555'
# base10 to base4
# >>> baseconvert(99,BASE10,"0123")
# '1203'
# base4 to base5 (with alphabetic digits)
# >>> baseconvert(1203,"0123","abcde")
# 'dee'
# base5, alpha digits back to base 10
# >>> baseconvert('dee',"abcde",BASE10)
# '99'
# decimal to a base that uses A-Z0-9a-z for its digits
# >>> baseconvert(257938572394L,BASE10,BASE62)
# 'E78Lxik'
# ..convert back
# >>> baseconvert('E78Lxik',BASE62,BASE10)
# '257938572394'
# binary to a base with words for digits (the function cannot convert this back)
# >>> baseconvert('1101',BASE2,('Zero','One'))
# 'OneOneZeroOne'
# make an integer out of the number
x=long(0)
for digit in str(number):
x = x*len(fromdigits) + fromdigits.index(digit)
# create the result in base 'len(todigits)'
res=""
while x>0:
digit = x % len(todigits)
res = todigits[digit] + res
x /= len(todigits)
return res
4번 : 1번을 이용한 N진수에서 N진수로 만드는 함수2
def nnconverter(number, fromdigits, todigits):
fromdigits_len, todigits_len = len(fromdigits), len(todigits)
number = str(number)
number_len = len(number)
tmp_dec=0
for idx, n in enumerate(number):
tmp = fromdigits_len ** (number_len-idx-1) * fromdigits.index(n)
tmp_dec += tmp
result=''
while tmp_dec > 0:
tmp_dec, mod = divmod(tmp_dec, todigits_len)
result += str(todigits[mod])
return result[::-1]
BASE2 = "01"
BASE10 = "0123456789"
BASE16 = "0123456789ABCDEF"
BASE20 = "0123456789abcdefghij"
BASE62 = "ABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789abcdefghijklmnopqrstuvwxyz"
print(nnconverter('31e', BASE20, BASE2))
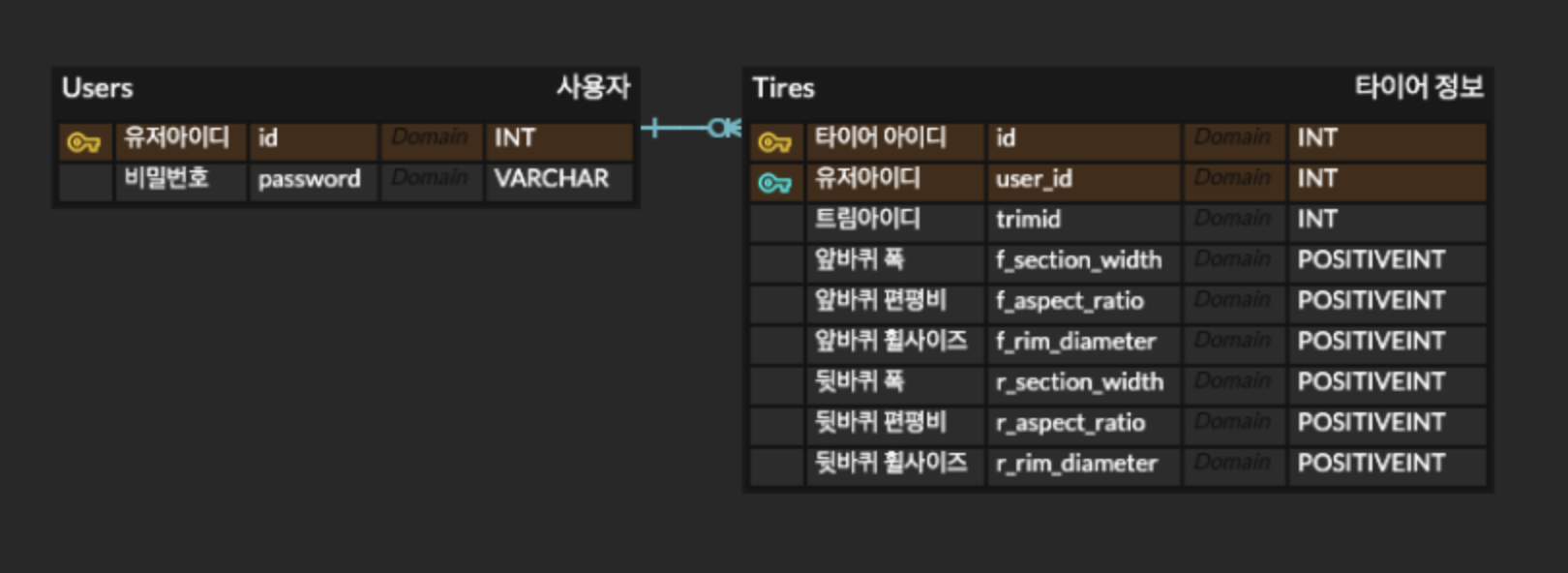
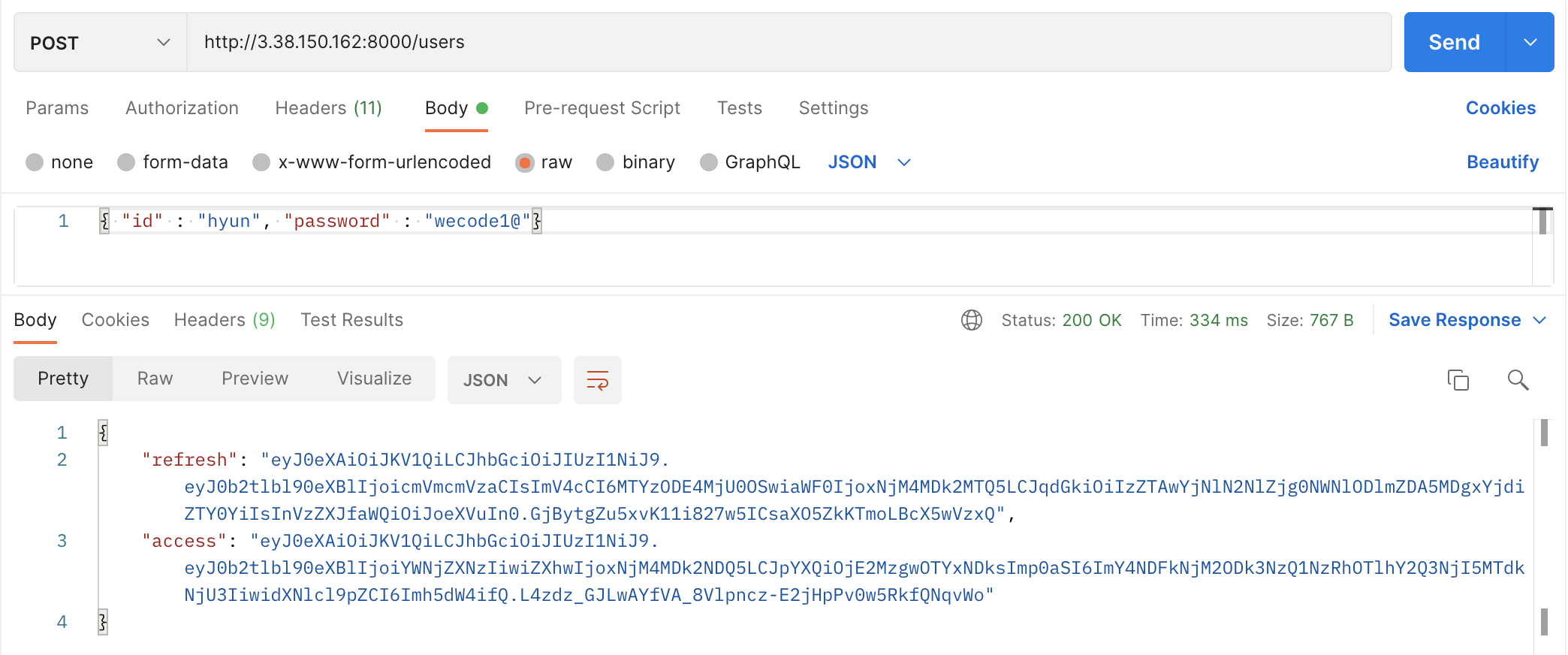
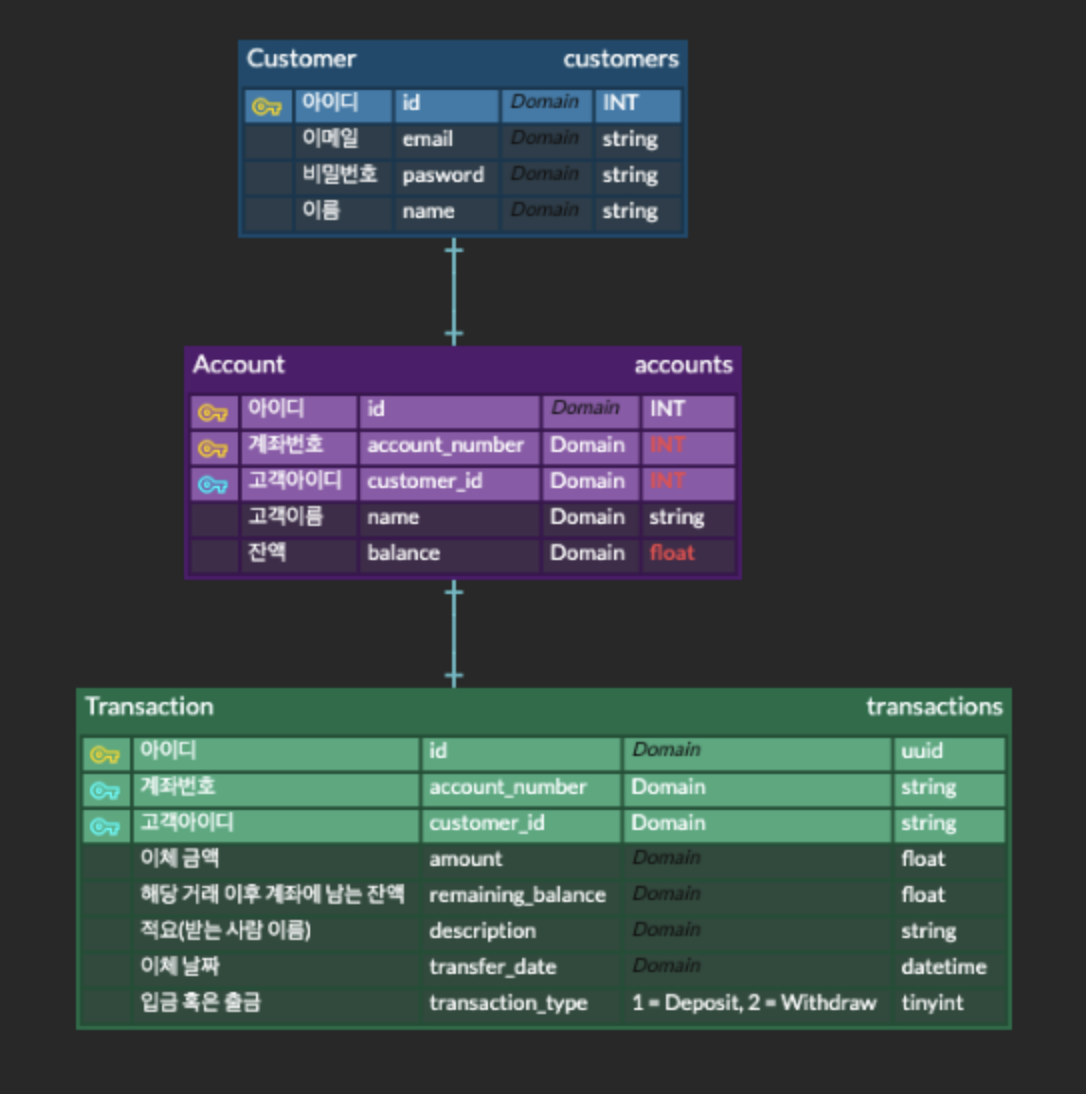
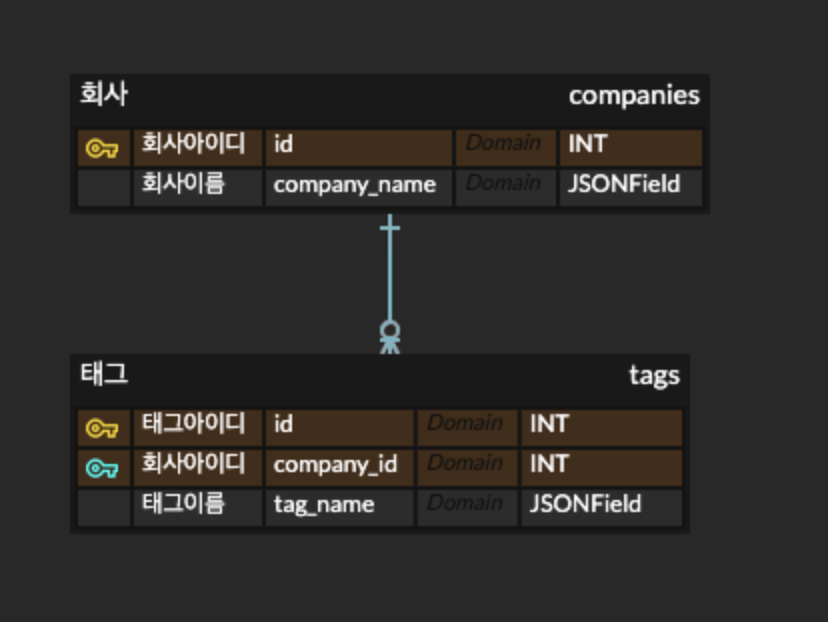
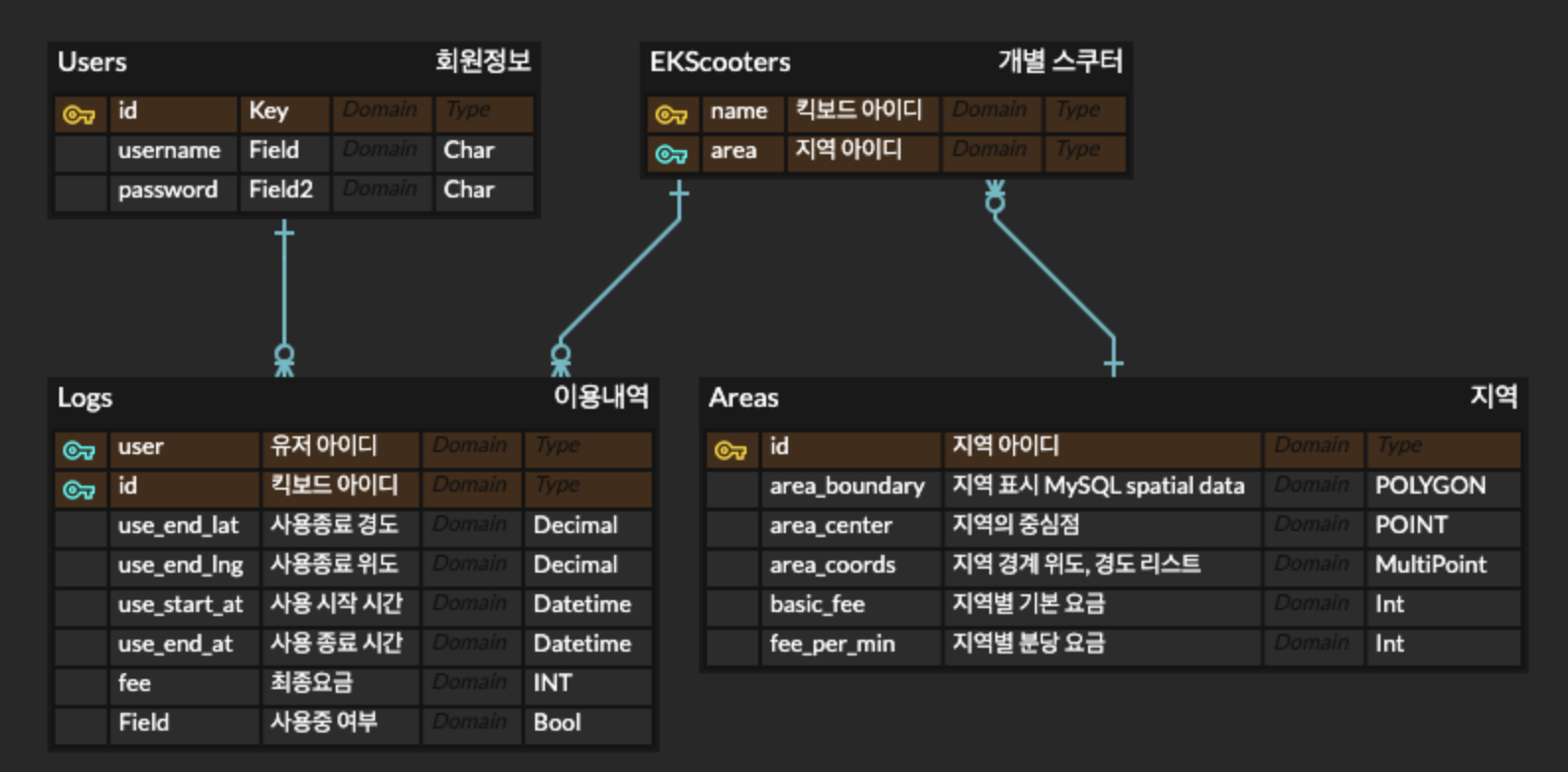 처음에 나는 이렇게 erd를 작성했다. 팀에서 최종적으로 사용한 모델링은 아래와 같다.
처음에 나는 이렇게 erd를 작성했다. 팀에서 최종적으로 사용한 모델링은 아래와 같다.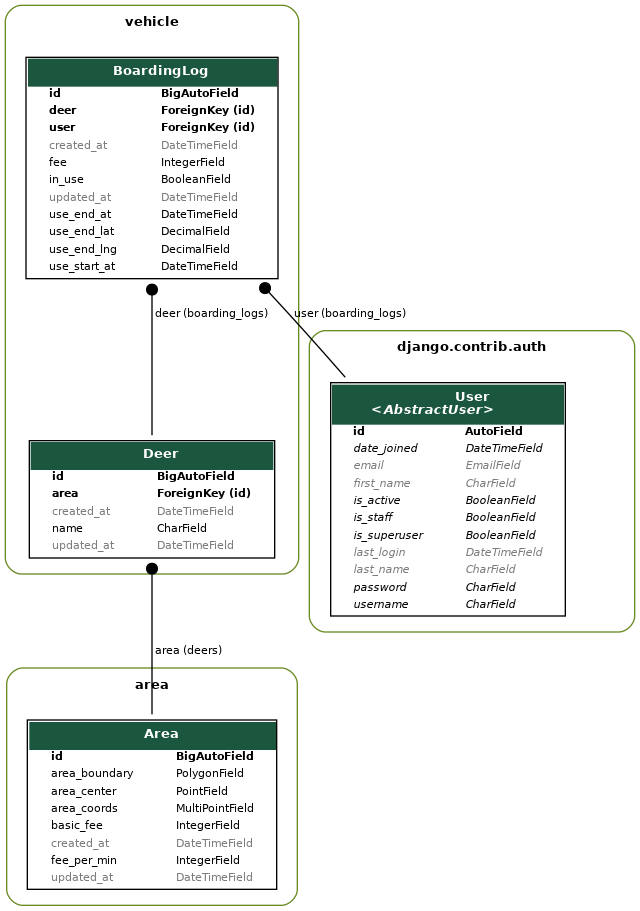
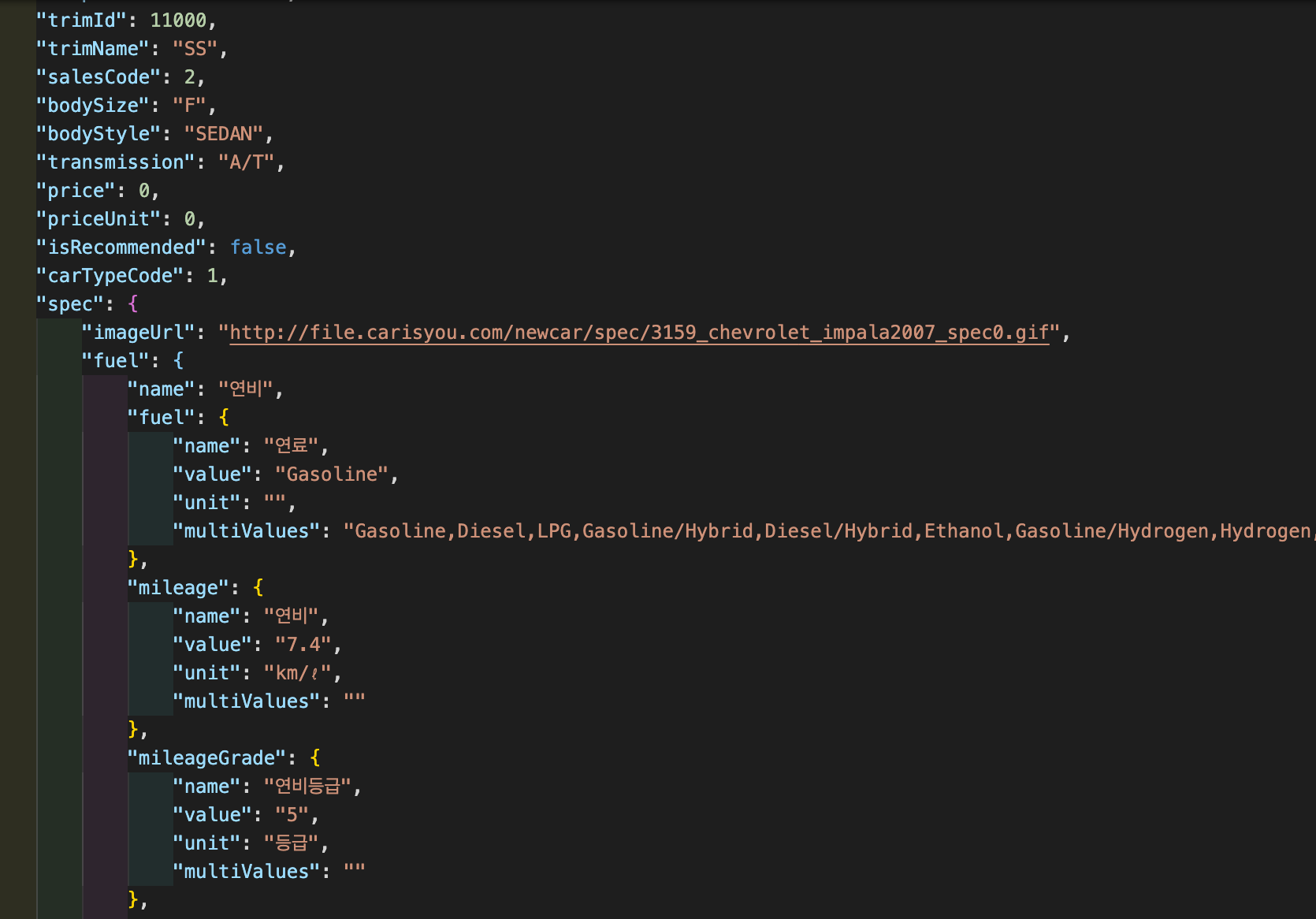
 API로 받게되는 공공데이터가 위와 같은 형태로 되어있었고, 이 형태 그대로 디비에 업로드하였다. 이 디비를 보고 과제번호와 과제이름, 학과(ex.소아과)와 담당기관, 연구종류와 임상시험단계 컬럼을 검색에 포함하는 것이 좋을 것 같다고 결정했다. 자세한 기준은 아래와 같다.
API로 받게되는 공공데이터가 위와 같은 형태로 되어있었고, 이 형태 그대로 디비에 업로드하였다. 이 디비를 보고 과제번호와 과제이름, 학과(ex.소아과)와 담당기관, 연구종류와 임상시험단계 컬럼을 검색에 포함하는 것이 좋을 것 같다고 결정했다. 자세한 기준은 아래와 같다.