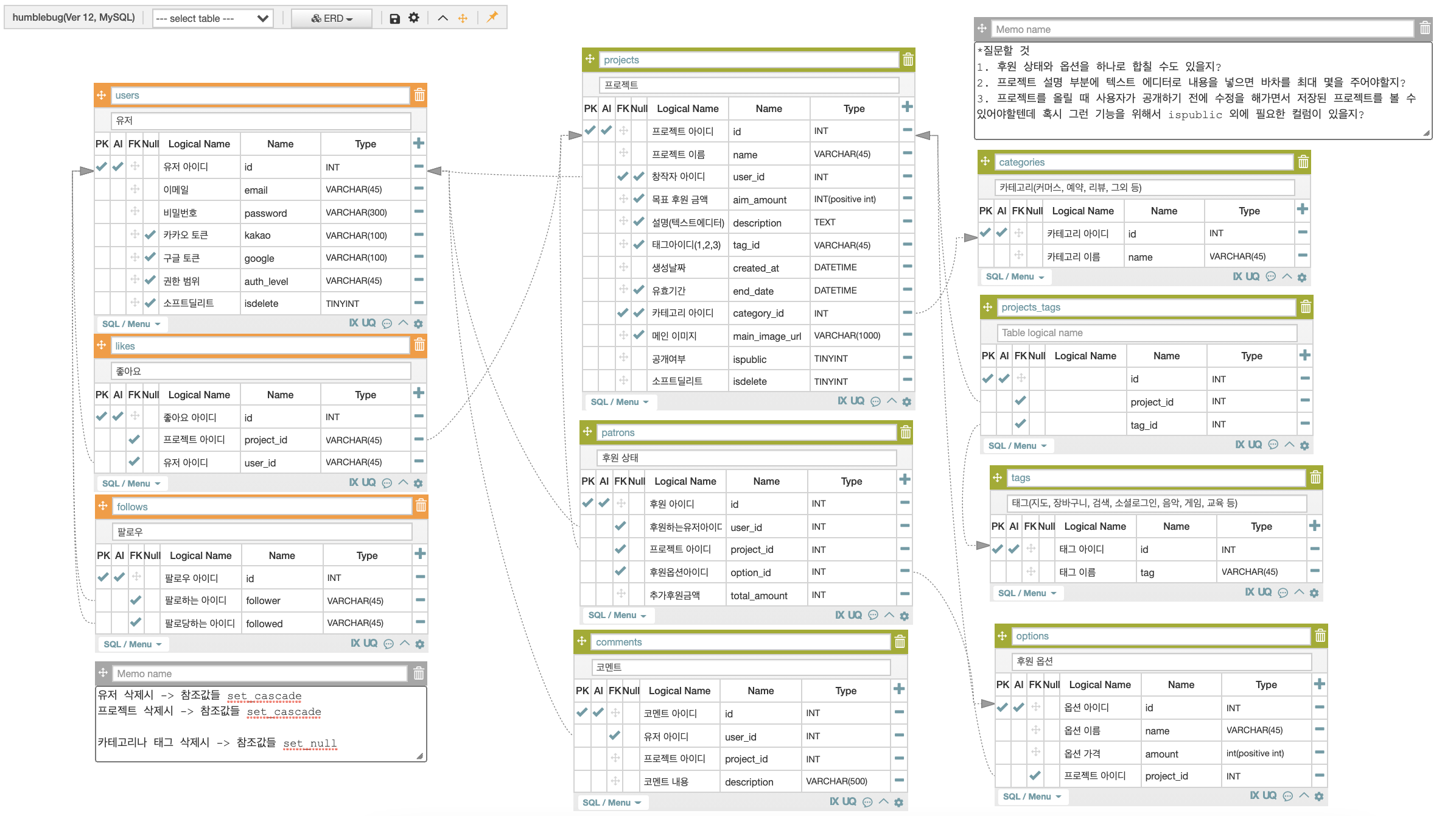
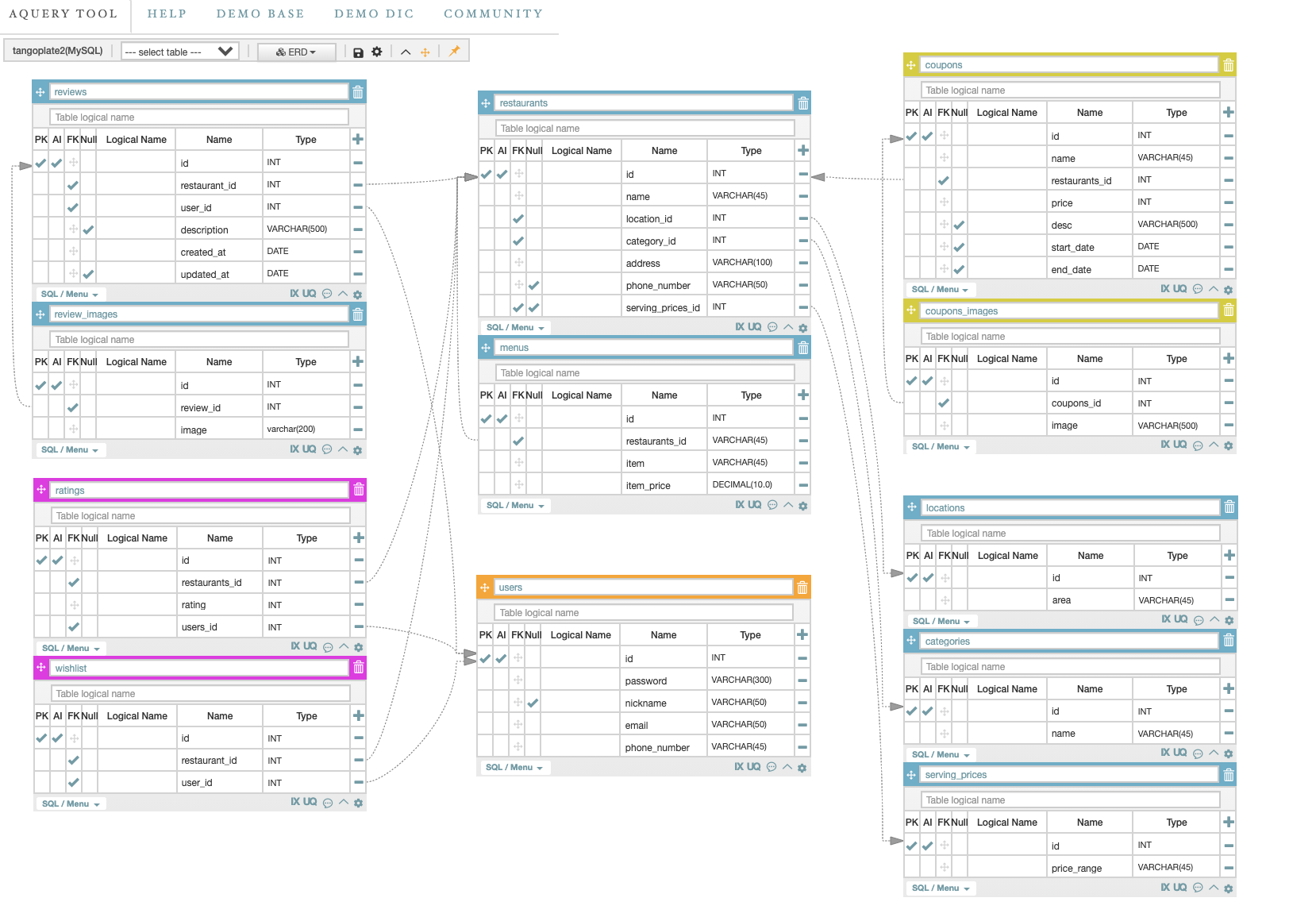
DAY1
Selection Sort(선택정렬)
정렬 알고리즘은 순서가 없던 데이터를 순서대로 바꾸어 나열하는 알고리즘입니다.
정렬을 하는 방법은 여러가지가 있는데, 그 중에 유명한 알고리즘은 아래 4가지가 있습니다.
오늘은 선택정렬을 배우겠습니다.
선택정렬은 정렬되지 않은 데이터 중 가장 작은 데이터를 선택해서
맨 앞에서부터 순서대로 정렬해 나가는 알고리즘입니다.
영어 설명 한 번 보시죠!
It has O(n2) time complexity, making it inefficient on large lists, and generally performs worse than the similar insertion sort.
Selection sort is noted for its simplicity, and it has performance advantages over more complicated algorithms in certain situations, particularly where auxiliary memory is limited.
예제를 통해 보겠습니다.
정렬을 해야하는 배열은 [7,5,4,2] 입니다.
첫 번째 loop에서는 index 0부터 3까지 확인하며 가장 작은 수를 찾습니다.
2 이므로 index 0의 7과 교체합니다. -> [2,5,4,7]
두 번째는 index 1부터 3까지 확인하며 가장 작은 수를 찾습니다.
4이므로 index 1의 5와 교체합니다 -> [2,4,5,7]
세 번째는 index 2부터 3까지.. 이런식으로 가장 작은 수를 선택해서 순서대로 교체하는 것을 선택정렬이라고 합니다.
Problem Statement
nums라는 정렬되지 않은 숫자 배열을 주면, 오름차순(1,2,3..10) 으로 정렬된 배열을 return해주세요.
선택정렬 알고리즘으로 구현하셔야겠죠??
제출코드
def selectionSort(nums):
for i in range(0,len(nums)):
temp = min(nums[i:])
nums[nums.index(min(nums[i:]))] = nums[i]
nums[i] = temp
return nums
DAY2
버블정렬(Bubble Sort)
버블 정렬은 인접한 데이터를 교환해서 정렬하는 알고리즘입니다.
알고리즘의 정렬되는 모습이 마치 거품처럼 보인다고 해서 붙여진 이름입니다.아래 그림을 한 번 봐주세요.
아마 바로 이해되실 것입니다.
아래와 같은 정렬되지 않은 수가 있을 때, index 0 <-> 1 부터 교환하기 시작합니다.
인접한 두 수를 비교하여 더 큰 것을 우측으로 이동시킵니다.
6 5 3 2 8
-> 5 6 3 2 8
그 다음은 index 1 <-> 2
5 6 3 2 8
-> 5 3 6 2 8
그 다음은 index 2 <-> 3
5 3 6 2 8
-> 5 3 2 6 8
그 다음은 index 3 <-> 4
5 3 2 6 8
-> 5 3 2 6 8
이렇게 제일 마지막 두 수 까지 비교하면, 제일 큰 수가 제일 마지막 index에 위치하는 것을 알 수 있습니다.
다시 처음부터 시작합니다.
5 3 2 6 8
-> 3 5 2 6 8
3 5 2 6 8
-> 3 2 5 6 8
3 2 5 6 8
-> 3 2 5 6 8
이번 교환에는 index 2까지 비교하고 멈추면 됩니다.
마지막 index는 이미 제일 큰 수가 정렬된 상태이기 때문입니다.
이런식으로 계속 비교하고 교체하면 됩니다.!
Problem
nums라는 배열을 주면, 버블정렬 알고리즘으로 배열을 정렬해주세요.
사고 과정
def bubbleSort(arr):
for i in range(0, len(arr)-1):
if arr[i] > arr[i + 1]:
arr[i], arr[i + 1] = arr[i + 1], arr[i]
return(arr)
이렇게하니 2번 테스트에서 에러가 났다.
모범 답안
def bubbleSort(arr):
n = len(arr)
for i in range(n):
for j in range(0, n - i - 1):
if arr[j] > arr[j + 1]:
arr[j], arr[j + 1] = arr[j + 1], arr[j]
return(arr)
DAY3
재귀(Recursion)
이전에 재귀를 배웠었습니다.
오늘은 재귀를 이용해 문제를 풀어주세요.
str 이라는 ‘string’을 넘겨주면 글자순서를 바꿔서 return해주세요.
reverse 메서드 사용은 당연히 금지입니다!
input: 'hello'
output: 'olleh'
힌트
아래의 코드가 어색한 것은 아니겠죠?
(함수의 return에 string을 붙여서 사용하는 것)
def getName(name):
return name
print(getName('김')+'님')
사고과정
def reverseString(str):
print(str[:-1])
return reverseString(str[:-1])
모범답안
def reverseString(str):
if len(str)==1:
return str[0]
return str[-1] + reverseString(str[:-1])
DAY4
연결리스트(Linked List)
아래 설명을 먼저 읽어주세요.
linked list에 대한 설명입니다.
Singly Linked List
singly linked list에 대해 조금 더 자세히 알아보겠습니다.
위의 stack overflow 설명과 같이, singly-linked list는 특정 index의 node value를 바로 얻을 수가 없습니다.
만약 i번째 요소를 얻고 싶으면 head node부터 node를 하나하나 탐색해야 알 수 있습니다.
예를 들어 head의 node가 23이라고 할 때, 3번째 node를 알고 싶으면 head의 next 값을 알아서 -> 2번째 node를 알아서 -> 2번째 node를 방문해야만 3번째 node를 알 수 있습니다.
2번째 node가 6이라고 한다면 head node 23의 next는 6이었을 것이고, 다시 6을 방문해 next 값을 얻는 식으로 하나하나 거치며 도달할 수 있습니다.
이렇게 array에 비교해 비효율적이어 보이는 linked list를 왜 쓸까 궁금해 할 수 있겠지만,insert, delete의 기능을 추가한 linked list를 직접 설계할 수 있다면 마치 array를 사용하는 것처럼 편할 것입니다.
코드 카타
linked list를 만들 수 있는 MyLinkedList 클래스를 설계해봅시다.
singly linked list 로 해도 되고, doubly linked list 로 구현하셔도 됩니다.
singly linked list를 구현하려면 val과 next라는 속성이 있어야 합니다.
val: 현재 node의 value
next: 다음 node를 가르키는 pointer(reference)
doubly linked list를 구현하려면 prev라는 속성이 하나 더 있어야 합니다.
prev: 이전 node를 가르키는 pointer(reference)
MyLinkedList 클래스에는 5가지 method가 있습니다.
아래의 설명을 참고하여 구현해주세요.
-
get(index) : linked list 의 index 번째 node의 value를 return해주세요. 값이 없으면 -1을 return해주세요.
-
addAtHead(val) : linked list 의 첫 번째 요소 전에 value가 val인 node를 추가해주세요. val이 추가되면 이 node는 linked list의 첫 번째 노드가 되는 것입니다.
-
addAtTail(val) : value가 val인 node를 linked list의 마지막에 추가해주세요.
-
addAtIndex(index, val) : value가 val인 node를 linked list의 index node 바로 전에 추가해주세요. 만약 index가 linked list의 길이와 같다면 제일 마지막에 추가하면 됩니다. 만약 index가 길이보다 길다면, node를 추가하지 말아주세요.
-
deleteAtIndex(index) : linked list의 index 번째 node를 삭제해주세요.
MyLinkedList 클래스는 아래와 같이 사용됩니다.
linkedList = MyLinkedList()
linkedList.addAtHead(1)
linkedList.addAtTail(3)
linkedList.addAtIndex(1, 2) // linked list는 1->2->3 가 됩니다.
linkedList.get(1) // returns 2
linkedList.deleteAtIndex(1) // linked list는 이제 1->3
linkedList.get(1) // returns 3
모범답안
class Node:
def __init__(self, value):
self.val = value
self.next = self.pre = None
def getNext(self):
return self.next
class MyLinkedList():
def __init__(self):
self.head = None
def get(self, index):
current = self.head
while index > 0 :
current = current.getNext()
index -= 1
return current.val
def addAtHead(self, val):
newNode = Node(val)
newNode.next = self.head
self.head = newNode
def addAtTail(self, val):
newNode = Node(val)
current = self.head
while current.next != None :
current = current.getNext()
current.next = newNode
def addAtIndex(self, index, val):
newNode = Node(val)
current = self.head
while index > 1 :
current = current.getNext()
index -= 1
newNode.next = current.getNext()
current.next = newNode
def deleteAtIndex(self, index):
current = self.head
while index > 1 :
current = current.getNext()
index -= 1
current.next = current.getNext().getNext()