개인적으로 복습할 용도로 명령어 위주로 적었어서 혹시 전체적인 흐름에 대해서 더 잘 알고싶다면 아래 두 분의 블로그를 추천한다.
홍데브님의 블로그
cmin님의 블로그
장고 설정
장고 프로젝트 시작
- Miniconda 가상환경 생성 및 가상환경 activate
conda create -n 가상환경이름 python=3.8
conda activate 가상환경이름
conda info --envs #설정한 가상환경 리스트 확인
mysql.server start
mysql -u root -p #마이sql시작
mysql> create database "NAME" character set utf8mb4 collate utf8mb4_general_ci;
- 프로젝트 시작을 위한 python package 설치
컴퓨터에 mysql응용프로그램이 켜져있으면 터미널로 열리지 않을 수 있다.
pip install 패키지이름 #파이썬 패키지 설치
pip install Django #장고 설치
pip install mysqlclient # mysqlclient설치 (mysql 먼저 설치 필요!!!)
pip install django-cors-headers #CORS 해결을 위한 패키지
pip freeze #가상환경 패키지 리스트 확인
django-admin startproject 프로젝트이름 #프로젝트 생성
cd 프로젝트이름 #프로젝트 디렉토리로 들어감
python manage.py startapp 앱이름 #앱 생성(manage.py가 존재하는 디렉토리에서)
settings.py 설정
from pathlib import Path #기존에 settings.py 에 있는 코드
from my_settings import DATABASES, SECRET_KEY
#시크릿 키와 데이터베이스 변수는 my_settings파일을 만들어서 갈음한다.
SECRET_KEY = SECRET_KEY # 기존의 시크릿키 변수 삭제 후 대체
DATABASES = DATABASES # 기존의 데이터베이스 변수 삭제 필수!
ALLOWED_HOSTS = ['*'] #수정 : 모두 접속 가능
APPEND_SLASH = False #추가 : 슬래시 자동으로 삽입하지 않음
INSTALLED_APPS = [
# 'django.contrib.admin', #admin도
# 'django.contrib.auth', #login auth도 직접 만들어쓸 예정이다
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'corsheaders', # corsheaders 추가
'products', #앱을 새로 만들면 여기에 추가해야한다
]
MIDDLEWARE = [
'django.middleware.security.SecurityMiddleware',
'django.contrib.sessions.middleware.SessionMiddleware',
'django.middleware.common.CommonMiddleware',
# 'django.middleware.csrf.CsrfViewMiddleware', csrf 주석처리
# 'django.contrib.auth.middleware.AuthenticationMiddleware', auth 주석처리
'django.contrib.messages.middleware.MessageMiddleware',
'django.middleware.clickjacking.XFrameOptionsMiddleware',
'corsheaders.middleware.CorsMiddleware', #corsheaders middleware 추가
]
# 데이터베이스 부분 삭제
# 뒷부분 생략
#REMOVE_APPEND_SLASH_WARNING 추가
APPEND_SLASH = False
##CORS
CORS_ORIGIN_ALLOW_ALL=True
CORS_ALLOW_CREDENTIALS = True
CORS_ALLOW_METHODS = (
'DELETE',
'GET',
'OPTIONS',
'PATCH',
'POST',
'PUT',
)
CORS_ALLOW_HEADERS = (
'accept',
'accept-encoding',
'authorization',
'content-type',
'dnt',
'origin',
'user-agent',
'x-csrftoken',
'x-requested-with',
#만약 허용해야할 추가적인 헤더키가 있다면?(사용자정의 키) 여기에 추가하면 됩니다.
)
위와 같이 settings.py를 추가 및 수정한다.
my_setting.py 파일 추가
시크릿 키와 디비정보가 깃에 공개적으로 노출되지 않도록 빼기 위해서
manage.py있는 디렉토리에 my_setting.py라는 새 파일을 만들어서 추가한다.
#클라우드에 올리지 않는, 키를 보관하는 파일
DATABASES = {
'default' : {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'westarbucks_db',
'USER': 'root',
'PASSWORD': '',
'HOST': '127.0.0.1', #데이터베이스의 IP주소, 이건 각자의 컴퓨터
'PORT': '3306',
}
}
SECRET_KEY ='_9^=58g2r*r(6@q7ugn!fxg-!fo48$7af9i4yn9-1$+...'
#setting.py에 있던 시크릿 키를 붙여넣음
urls.py수정
from django.urls import path
urlpatterns = [
]
데이터베이스 생성
mysql -u root -p #마이sql시작
show databases; --mysql의 모든 db들 보여주기
use [데이터베이스이름]; --사용할 db골라주기
create database [데이터베이스이름] character set utf8mb4 collate utf8mb4_general_ci; --데이터베이스 생성 및 utf8설정(한중일)
show tables; --db안의 모든 테이블들 보여주기
mysql 나가기 키는 \q
gitignore추가 (manage.py가 존재하는 디렉토리에)
소스를 공유하기 위해 깃을 사용하지만 올리고 싶은것 올리고 싶지 않은것, 올려서는 안되는 것들이 존재하고 이를 구분하기 위해 깃이 설치된 디렉토리에 .gitignore파일을 생성해서 관리해야 한다.
gitignore.io
위의 사이트에서 사용하는 환경에 해당하는 키워드를 선택하면, 자동으로 .gitignore 파일에 정의할 요소들을 생성해준다.
python,pycharm,visualstudiocode,vim,macos,linux,zsh
이 키워드들을 추가해서 파일을 만들고 마지막에 my_settings.py도 추가해준다.
보안관련파일과 크롤링파일
my_settings.py (보안 관련 파일은 github에 업로드되면 안된다.)
*.csv (crwaling한 파일 역시 업로드하지 않는다.)
git ignore 펼쳐서 보기/접기
# Created by https://www.toptal.com/developers/gitignore/api/python,pycharm,visualstudiocode,vim,macos,linux,zsh
# Edit at https://www.toptal.com/developers/gitignore?templates=python,pycharm,visualstudiocode,vim,macos,linux,zsh
### Linux
\*~
# temporary files which can be created if a process still has a handle open of a deleted file
.fuse_hidden\*
# KDE directory preferences
.directory
# Linux trash folder which might appear on any partition or disk
.Trash-\*
# .nfs files are created when an open file is removed but is still being accessed
.nfs\*
### macOS
# General
.DS_Store
.AppleDouble
.LSOverride
# Icon must end with two \r
Icon
# Thumbnails
.\_\*
# Files that might appear in the root of a volume
.DocumentRevisions-V100
.fseventsd
.Spotlight-V100
.TemporaryItems
.Trashes
.VolumeIcon.icns
.com.apple.timemachine.donotpresent
# Directories potentially created on remote AFP share
.AppleDB
.AppleDesktop
Network Trash Folder
Temporary Items
.apdisk
### PyCharm
# Covers JetBrains IDEs: IntelliJ, RubyMine, PhpStorm, AppCode, PyCharm, CLion, Android Studio, WebStorm and Rider
# Reference: https://intellij-support.jetbrains.com/hc/en-us/articles/206544839
# User-specific stuff
.idea/**/workspace.xml
.idea/**/tasks.xml
.idea/**/usage.statistics.xml
.idea/**/dictionaries
.idea/\*\*/shelf
# AWS User-specific
.idea/\*\*/aws.xml
# Generated files
.idea/\*\*/contentModel.xml
# Sensitive or high-churn files
.idea/**/dataSources/
.idea/**/dataSources.ids
.idea/**/dataSources.local.xml
.idea/**/sqlDataSources.xml
.idea/**/dynamic.xml
.idea/**/uiDesigner.xml
.idea/\*\*/dbnavigator.xml
# Gradle
.idea/**/gradle.xml
.idea/**/libraries
# Gradle and Maven with auto-import
# When using Gradle or Maven with auto-import, you should exclude module files,
# since they will be recreated, and may cause churn. Uncomment if using
# auto-import.
# .idea/artifacts
# .idea/compiler.xml
# .idea/jarRepositories.xml
# .idea/modules.xml
# .idea/\*.iml
# .idea/modules
# \*.iml
# \*.ipr
# CMake
cmake-build-\*/
# Mongo Explorer plugin
.idea/\*\*/mongoSettings.xml
# File-based project format
\*.iws
# IntelliJ
out/
# mpeltonen/sbt-idea plugin
.idea_modules/
# JIRA plugin
atlassian-ide-plugin.xml
# Cursive Clojure plugin
.idea/replstate.xml
# Crashlytics plugin (for Android Studio and IntelliJ)
com_crashlytics_export_strings.xml
crashlytics.properties
crashlytics-build.properties
fabric.properties
# Editor-based Rest Client
.idea/httpRequests
# Android studio 3.1+ serialized cache file
.idea/caches/build_file_checksums.ser
### PyCharm Patch
# Comment Reason: https://github.com/joeblau/gitignore.io/issues/186#issuecomment-215987721
# \*.iml
# modules.xml
# .idea/misc.xml
# \*.ipr
# Sonarlint plugin
# https://plugins.jetbrains.com/plugin/7973-sonarlint
.idea/\*\*/sonarlint/
# SonarQube Plugin
# https://plugins.jetbrains.com/plugin/7238-sonarqube-community-plugin
.idea/\*\*/sonarIssues.xml
# Markdown Navigator plugin
# https://plugins.jetbrains.com/plugin/7896-markdown-navigator-enhanced
.idea/**/markdown-navigator.xml
.idea/**/markdown-navigator-enh.xml
.idea/\*\*/markdown-navigator/
# Cache file creation bug
# See https://youtrack.jetbrains.com/issue/JBR-2257
.idea/$CACHE_FILE$
# CodeStream plugin
# https://plugins.jetbrains.com/plugin/12206-codestream
.idea/codestream.xml
### Python
# Byte-compiled / optimized / DLL files
**pycache**/
_.py[cod]
_$py.class
# C extensions
\*.so
# Distribution / packaging
.Python
build/
develop-eggs/
dist/
downloads/
eggs/
.eggs/
lib/
lib64/
parts/
sdist/
var/
wheels/
share/python-wheels/
_.egg-info/
.installed.cfg
_.egg
MANIFEST
# PyInstaller
# Usually these files are written by a python script from a template
# before PyInstaller builds the exe, so as to inject date/other infos into it.
_.manifest
_.spec
# Installer logs
pip-log.txt
pip-delete-this-directory.txt
# Unit test / coverage reports
htmlcov/
.tox/
.nox/
.coverage
.coverage._
.cache
nosetests.xml
coverage.xml
_.cover
\*.py,cover
.hypothesis/
.pytest_cache/
cover/
# Translations
_.mo
_.pot
# Django stuff:
\*.log
local_settings.py
db.sqlite3
db.sqlite3-journal
# Flask stuff:
instance/
.webassets-cache
# Scrapy stuff:
.scrapy
# Sphinx documentation
docs/\_build/
# PyBuilder
.pybuilder/
target/
# Jupyter Notebook
.ipynb_checkpoints
# IPython
profile_default/
ipython_config.py
# pyenv
# For a library or package, you might want to ignore these files since the code is
# intended to run in multiple environments; otherwise, check them in:
# .python-version
# pipenv
# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
# However, in case of collaboration, if having platform-specific dependencies or dependencies
# having no cross-platform support, pipenv may install dependencies that don't work, or not
# install all needed dependencies.
#Pipfile.lock
# PEP 582; used by e.g. github.com/David-OConnor/pyflow
**pypackages**/
# Celery stuff
celerybeat-schedule
celerybeat.pid
# SageMath parsed files
\*.sage.py
# Environments
.env
.venv
env/
venv/
ENV/
env.bak/
venv.bak/
# Spyder project settings
.spyderproject
.spyproject
# Rope project settings
.ropeproject
# mkdocs documentation
/site
# mypy
.mypy_cache/
.dmypy.json
dmypy.json
# Pyre type checker
.pyre/
# pytype static type analyzer
.pytype/
# Cython debug symbols
cython_debug/
### Vim
# Swap
[._]_.s[a-v][a-z]
!_.svg # comment out if you don't need vector files
[._]\*.sw[a-p]
[._]s[a-rt-v][a-z]
[._]ss[a-gi-z]
[._]sw[a-p]
# Session
Session.vim
Sessionx.vim
# Temporary
.netrwhist
# Auto-generated tag files
tags
# Persistent undo
[._]\*.un~
### VisualStudioCode
.vscode/_
!.vscode/settings.json
!.vscode/tasks.json
!.vscode/launch.json
!.vscode/extensions.json
_.code-workspace
# Local History for Visual Studio Code
.history/
### VisualStudioCode Patch
# Ignore all local history of files
.history
.ionide
### Zsh
# Zsh compiled script + zrecompile backup
_.zwc
_.zwc.old
# Zsh completion-optimization dumpfile
_zcompdump_
# Zsh zcalc history
.zcalc_history
# A popular plugin manager's files
.\_zinit
.zinit_lstupd
# zdharma/zshelldoc tool's files
zsdoc/data
# robbyrussell/oh-my-zsh/plugins/per-directory-history plugin's files
# (when set-up to store the history in the local directory)
.directory_history
# MichaelAquilina/zsh-autoswitch-virtualenv plugin's files
# (for Zsh plugins using Python)
# Zunit tests' output
/tests/\_output/\*
!/tests/\_output/.gitkeep
# End of https://www.toptal.com/developers/gitignore/api/python,pycharm,visualstudiocode,vim,macos,linux,zsh
#보안관련파일과 크롤링파일
my_settings.py
*.csv
실행
pythong manage.py runserver
requirements.txt 추가
pip freeze > requirements.txt
이렇게 manage.py가 있는 디렉토리에 설치된 라이브러리의 버전을 명시해준다.
Django==3.2.6
django-cors-headers==3.7.0
mysql-client==0.0.1
PyMySQL==1.0.2 #맥 M1의 경우 설치한 파일
장고에서 자동으로 설치되는 것을 제외하고 직접 설치한 것들만 남겨주면 좋다.
디렉토리 구조
#(참고) 프로젝트 디렉토리 구조 구조
.
└── suntae
├── manage.py
├── my_settings.py
└── westagram
├── \__init__.py
├── asgi.py
├── settings.py
├── urls.py
└── wsgi.py
CRUD 1
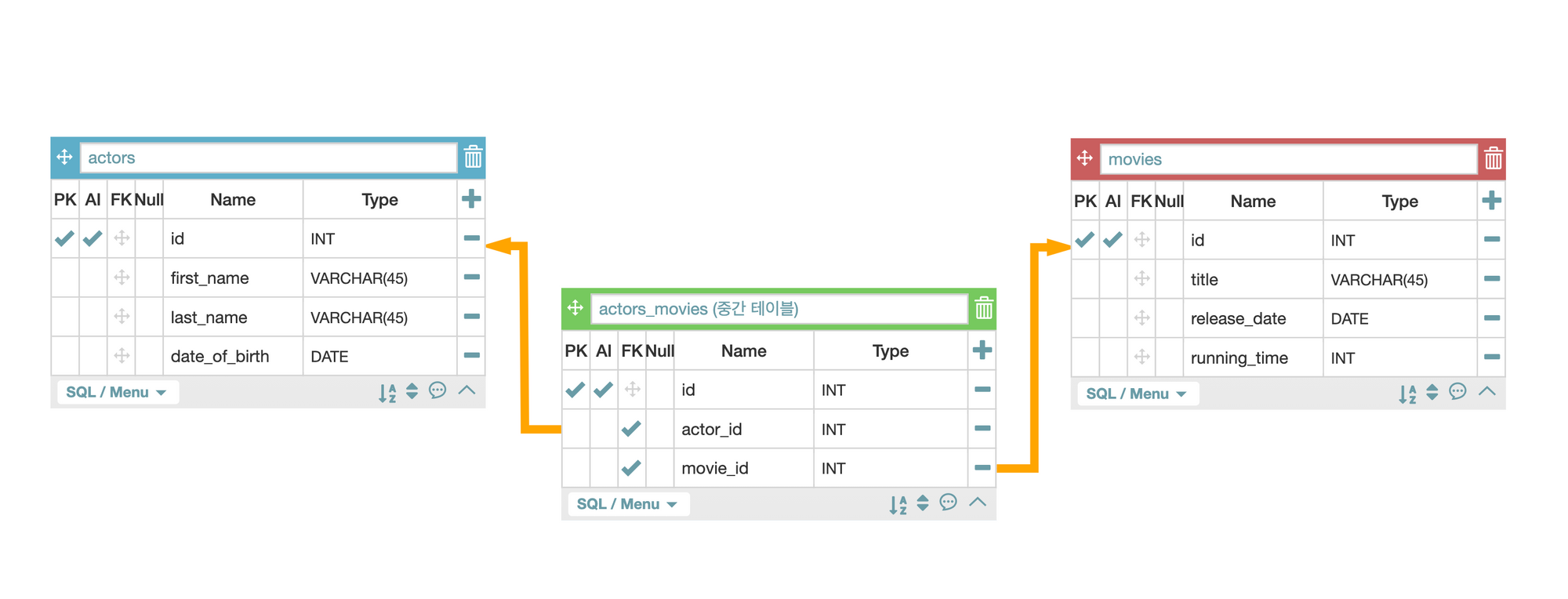
ERD테이블
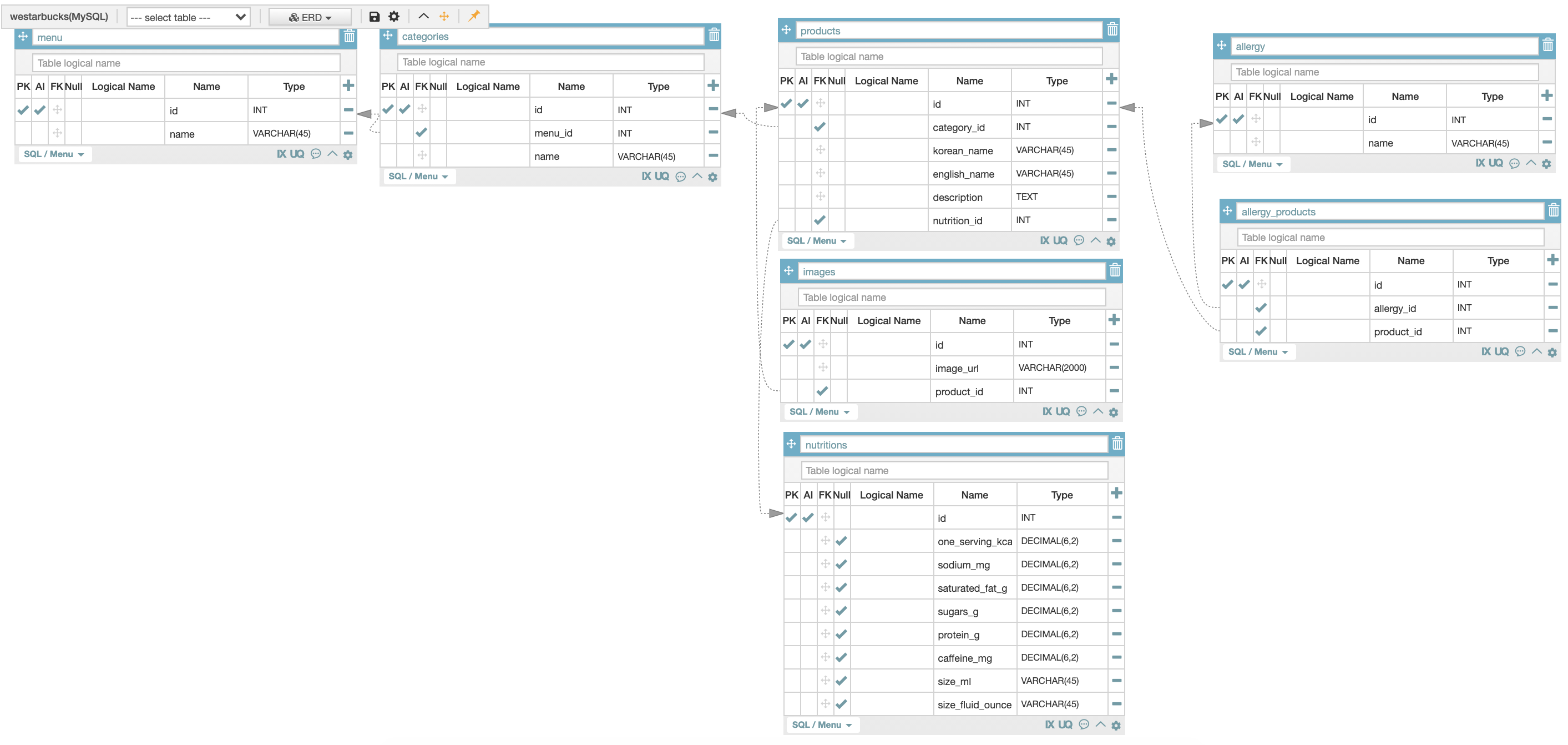 스타벅스 페이지를 보고 데이터 관계도를 만든다.
새로 생성된 앱의 models.py에 아래 migration을 넣어서 데이터베이스 토대를 만들어준다.
스타벅스 페이지를 보고 데이터 관계도를 만든다.
새로 생성된 앱의 models.py에 아래 migration을 넣어서 데이터베이스 토대를 만들어준다.
migration
models.py 펼쳐서 보기/접기
from django.db import models
class Menu(models.Model):
name = models.CharField(max_length=45)
#id는 장고가 자동으로 만들어주니까 클래스 객체에 안 넣어도 됨
class Meta: #테이블 이름 지정
db_table = 'menus' #안 쓰면 products_menus라고 컬럼이름 자동 생성
def __str__(self):
return self.name
class Category(models.Model):
name = models.CharField(max_length=45)
menu = models.ForeignKey('Menu', on_delete=models.CASCADE, default='')
#default에러가 떠서 디폴트를 추가했다
#외래키 쓸 때 장고가 알아서 _id를 붙여서 데이터베이스에 넘겨서 _id를 안 써도 된다.
class Meta:
db_table='categories'
def __str__(self):
return self.name
class Product(models.Model):
korean_name = models.CharField(max_length=45, default='')
english_name = models.CharField(max_length=45, default='')
description = models.TextField(max_length=300, default='')
isnew = models.BooleanField(default=False)
category = models.ForeignKey('Category', on_delete=models.CASCADE) #cascade : 부모개체가 사라지면 자식도 사라지도록
class Meta:
db_table = 'products'
# def __str__(self):
# return self.name
# 객체에 name이 없는데 위의 매쏘드를 넣었다가 쿼리셋 작성시 Attribution 에러가 났었다.
class Image(models.Model):
image_url = models.URLField(max_length=2000)
product = models.ForeignKey('Product', on_delete=models.CASCADE)
class Meta:
db_table = 'images'
class Allergy(models.Model):
name = models.CharField(max_length=45)
products = models.ManyToManyField('Product', through='AllergyProduct')
class Meta:
db_table = 'allergies'
class AllergyProduct(models.Model):
allergy = models.ForeignKey('Allergy',on_delete=models.CASCADE)
product = models.ForeignKey('Product', on_delete=models.CASCADE)
class Meta:
db_table = 'allergies_products'
class Nutrition(models.Model):
kcal = models.DecimalField(max_digits=5, decimal_places=1, null=True)
sodium = models.DecimalField(max_digits=5, decimal_places=1, null=True)
s_fat = models.DecimalField(max_digits=5, decimal_places=1, null=True)
sugar = models.DecimalField(max_digits=5, decimal_places=1, null=True)
protein = models.DecimalField(max_digits=5, decimal_places=1, null=True)
caffeine = models.DecimalField(max_digits=5, decimal_places=1, null=True)
product = models.OneToOneField('Product', on_delete=models.CASCADE)
class Meta:
db_table = 'nutritions'
처음에 뭔가 잘못 만들어서 마이그레이션 파일을 지우고 초기화했다. models.py를 처음 만들때 정성스럽게 만들어야할 것 같다.
migration 초기화하기
데이터베이스를 다 날려도 괜찮은 경우에 아래의 방법으로 마이그레이션을 재설정할 수 있다.
- 마이그레이션 폴더에서 __init__.py을 제외한 모든 파일을 삭제하거나 Unix OS의 경우 아래 명령어를 실행한다.
find . -path "*/migrations/*.py" -not -name "__init__.py" -delete
find . -path "*/migrations/*.pyc" -delete
- sql에서 모든 테이블을 드랍한다.
DROP DATABASE westarbucks_db; --db 전체 삭제
create database westarbucks_db character set utf8mb4 collate utf8mb4_general_ci; --데이터베이스 생성 및 utf8설정
- 마이그레이션을 다시 실행한다.
python manage.py makemigrations
python manage.py migrate
출처: How to Reset Migrations
migration 만들고 migrate 실행하기
python manage.py makemigrations
#모델의 변경사항을 파악, 설계도 작성(하고나서 만들어진 파일을 잘 살펴본다)
python manage.py showmigrations
#현재 migrations가 어떤 상태인지 살펴보기
python manage.py sqlmigrate [앱이름] [마이그레이션번호]
#실제 데이터베이스에 전달되는 SQL 쿼리문을 확인
python manage.py migrate
#자동으로 migration을 실행
migration을 만드는 것과 migrate는 각각
클래스에 맞게 설계도를 만들고 설계한대로 데이터베이스를 건설하겠다는 뜻이라고 할 수 있다.
SQL
select * from django_migrations; --장고 마이그레이션 보여주기
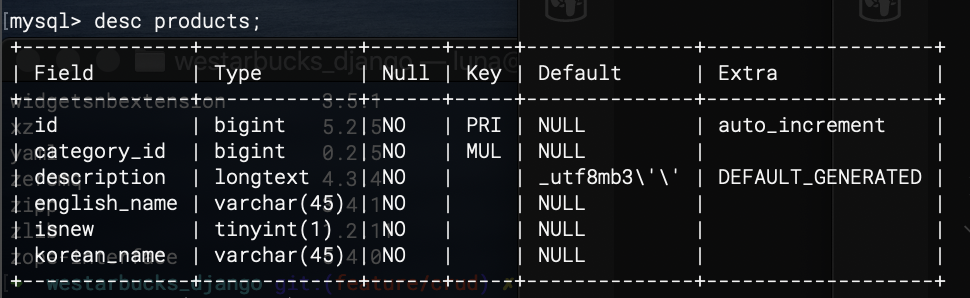
desc products; --프로덕츠 테이블이 잘 만들어졌는지 보여준다
마지막 명령어를 치면 해당 테이블 컬럼들의 조건식들이 잘 만들어졌는지 볼 수 있다.
QuerySet으로 CRUD하기
Django의 QuerySet API는 데이터 작업을 위한 포괄적인 메서드를 제공한다.
※ QuerySet: Django에 내장 된 일반적인 데이터 관리 기능
일반적으로 자주 사용되는 Model method를, 정확하게는 QuerySet method들은 아래와 같다.
Model method의 실행 결과는 QuerySet을 반환하거나 그렇지 않은 경우가 있다.
- Model method 종류
all() , filter() , exclude() , values() , values_list() , get() , create() ,
count() , exists() , update() , delete() , first() , last() ..
- QuerySet을 반환하는 경우
<QuerySet [<Category: Category object (1)>, <Category: Category object (2)>]>
(장고에서 만든 클래스의 인스턴스, 객체들이 모여 있는 리스트)
- 그렇지 않은 경우
<Category: Category object (1)> , 9 , True ..
QuerySet을 반환하지않는 Model method
create()
Table에 데이터를 추가(INSERT) 해주는 method로, 생성된 인스턴스를 반환해준다.
In : Category.objects.create(name='콜드브루')
Out : <Category: Category object (1)>
#category 변수에 반환된 값을 저장하고, 생성된 data를 사용할 수 있다.
#인스턴스로 반환되므로 category.name으로 class 안에 변수에 접근할 수 있다.
In : category = Category.objects.create(name='콜드브루')
In : category.name
Out : '콜드브루'
참고) save method : INSERT 또는 UPDATE
Category(name='콜드브루').save()
get()
지정된 조회 매개 변수와 일치하는 인스턴스를 반환합니다.이 매개 변수는 필드 조회에 설명 된 형식이어야합니다.
In : Category.objects.get(id=1)
Out : <Category: Category object (1)>
update()
지정된 필드에 대해 업데이트 쿼리를 수행하고 일치하는 행 수를 반환한다.
(일부 행에 이미 새 값이있는 경우 업데이트 된 행 수와 같지 않을 수 있음).
In : Category.objects.filter(name='탄산').update(name='콜드브루')
Out : 2 #총 업데이트된 row 개수
delete()
QuerySet의 모든 행에 대해 SQL 삭제 쿼리를 수행하고 삭제 된 개체 수와 개체 유형별 삭제 횟수가 있는 dictionary를 반환합니다.
In : Category.objects.filter(name='qp').delete()
Out : (1, {'products.Category': 1})
save()
INSERT 또는 UPDATE 를 수행하는 method로, 단일 객체에 대해서 업데이트를 수행할 때 많이 사용된다.
In : category = Category.objects.get(id=2)
Out : <Category: Category object (2)>
In : category.name
Out : '브루드커피'
In : category.name = 'new name'
In : category.save()
In : category.name
Out : 'new name'
QuerySet을 반환하는 Model method
all()
한 테이블의 모든 레코드를 가져오려면 아래와 같이 all() method를 사용합니다. 그 결과로 QuerySet 을 반환합니다. 이때, QuerySet 안에는 각각 인스턴스가 포함되어 있습니다.
In : Category.objects.all()
Out : <QuerySet [<Category: Category object (2)>, <Category: Category object (3)>, <Category: Category object (4)>, <Category: Category object (5)>, <Category: Category object (6)>, <Category: Category object (7)>]>
In : for category in Category.objects.all()
print(category.name)
#아래와 같이 인스턴스들이 담겨 있는 QuerySet이 반환되기 때문에, 모든 속성에 접근해서 데이터를 관리할 수 있습니다.
Out : 티
브루드커리
브루드커피
콜드브루
콜드브루
filter() & exclude()
한 테이블의 특정 레코드를 가져오려면 필터를 사용할 수 있다. filter() method는 가장 자주 사용하는 필터 기능이다. filter(**kwargs): 키워드 인자로 주어진 lookup 조건에 일치하는 레코드들의 QuerySet을 반환한다.
case1
In : Category.objects.filter(name='브루드커피')
Out : [<Category: Category object (3)>, <Category: Category object (4)>]
case2
In : Category.objects.filter(name='브루드커피').filter(id=3)
Out : [<Category: Category object (3)>]
case3
In : Category.objects.filter(name='브루드커피').exclude(id=3)
Out : [<Category: Category object (4)>]
values()
iterable로 사용될 때 모델 인스턴스가 아닌 dictionary을 포함하는 QuerySet을 반환합니다.
In : Category.objects.filter(name='브루드커피')
Out : [<Category: Category object (3)>, <Category: Category object (4)>]
In : Category.objects.filter(name='브루드커피').values()
Out : <QuerySet [{'id': 3, 'name': '브루드커피', 'created_at': datetime.datetime(2020, 9, 8, 5, 43, 30, 4068, tzinfo=<UTC>), 'updated_at': datetime.datetime(2020, 9, 8, 5, 43, 30, 21801, tzinfo=<UTC>)}, {'id': 4, 'name': '브루드커피', 'created_at': datetime.datetime(2020, 9, 8, 5, 43, 30, 4068, tzinfo=<UTC>), 'updated_at': datetime.datetime(2020, 9, 8, 5, 43, 30, 21801, tzinfo=<UTC>)}]>
values_list()
values_list() method는 dictionary를 반환하는 대신 반복 될 때 튜플을 반환한다는 점을 제외하면 values ()와 유사합니다. 각 튜플에는 values_list () 호출에 전달 된 각 필드 또는 표현식의 값이 포함되어 있으므로 첫 번째 항목이 첫 번째 필드입니다.
In : Category.objects.filter(name='브루드커피').values_list()
Out : <QuerySet [(3, '브루드커피', datetime.datetime(2020, 9, 8, 5, 43, 30, 4068, tzinfo=<UTC>), datetime.datetime(2020, 9, 8, 5, 43, 30, 21801, tzinfo=<UTC>)), (4, '브루드커피', datetime.datetime(2020, 9, 8, 5, 43, 30, 4068, tzinfo=<UTC>), datetime.datetime(2020, 9, 8, 5, 43, 30, 21801, tzinfo=<UTC>))]>
CREATE
장고에서 미리 있는 models.Model을 이용해서 Person.objects.create 매쏘드를 이용해서 데이터를 만들 수 있다.
python manage.py shell #파이썬에서 쉘 열기
>>>from products.models import Menu
#쉘에서 장고를 연결해주려면 import해야함, 시작 전 작성한 모델 클래스 import
>>> Menu.objects.create(name = '음료') #class명.objects.method명(~~)
exit() 하면 쉘을 종료할 수 있다.
주의 : shell을 켤때마다 from products.models import Menu 클래스를 임포트해주어야한다.
위와같이 입력하면 Menu클래스를 이용하여 ‘음료’가 name컬럼에 삽입된 것을 볼 수 있다.
왠지 모르겠지만 쌍따옴표를 쓰니까 에러가 나서 작은따옴표를 썼다.
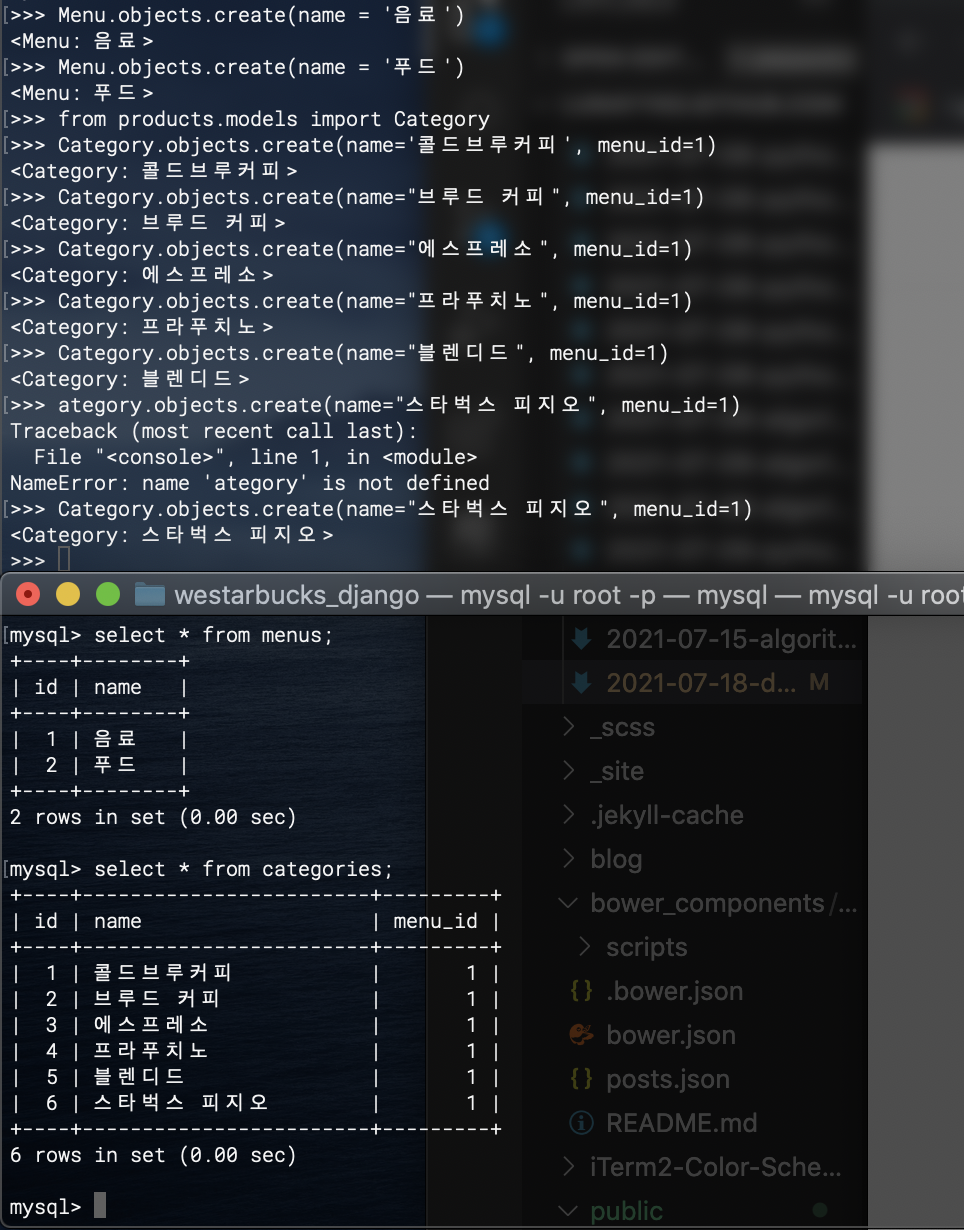
이번에는 영양성분표를 넣어보자
from products.models import Nutrition
Nutrition.objects.create(product_id=1, one_serving_kcal=75, sodium_mg=20, saturated_fat_g=2, sugars_g=10, caffeine_mg=245)
product_id를 1로 하고 싶은데 내가 저번에 쓰다지웠다해서 그런지 product_id=1자리가 비워져있지 않다. 테이블을 드랍한 뒤에 다시 시도해본다.
mysql> drop table nutritions;
드랍했더니 테이블 자체가 사라져버렸다 ㅋㅋㅋㅋㅋ 원래 컬럼값이 마음에 안 들었으니 테이블을 sql구문으로 다시 만들어보자. 데이터만 지우려면 Truncate를 사용해야한다.
class Nutrition(models.Model):
kcal = models.DecimalField(max_digits=5, decimal_places=1, null=True)
sodium = models.DecimalField(max_digits=5, decimal_places=1, null=True)
s_fat = models.DecimalField(max_digits=5, decimal_places=1, null=True)
sugar = models.DecimalField(max_digits=5, decimal_places=1, null=True)
protein = models.DecimalField(max_digits=5, decimal_places=1, null=True)
caffeine = models.DecimalField(max_digits=5, decimal_places=1, null=True)
product = models.OneToOneField('Product', on_delete=models.CASCADE)
class Meta:
db_table = 'nutritions'
이걸 sql로 다시 쓰면 아래와 같다.
CREATE TABLE nutritions
(
id INTEGER NOT NULL,
product_id INTEGER,
kcal DECIMAL(5,1),
sodium DECIMAL(5,1),
s_fat DECIMAL(5,1),
sugar DECIMAL(5,1),
protein DECIMAL(5,1),
caffeine DECIMAL(5,1),
PRIMARY KEY (id),
FOREIGN KEY (product_id) REFERENCES products (id)
);
외래키가 중복된다고 에러가 난다!
ERROR 3780 (HY000): Referencing column ‘product_id’ and referenced column ‘id’ in foreign key constraint ‘nutritions_ibfk_1’ are incompatible.
sql문에서 외래키부분(FOREIGN KEY (product_id) REFERENCES products (id))을 제외하고 실행해서 테이블을 다시 만들었다.
ALTER TABLE nutritions
ADD FOREIGN KEY (product_id) REFERENCES products(id);
위 명령어를 이용해 sql로 외래키를 추가하려고 했는데 3780에러가 계속 났다.
인터넷에서 검색하다보니 mysql에서 보이지는 않지만 외래키 constraint 설정되어있는 것과 관련이 있는 것 같다. 모든 constraint를 보는 명령어를 쳐봤다.
select * from information_schema.table_constraints where constraint_schema = 'westarbucks_db';
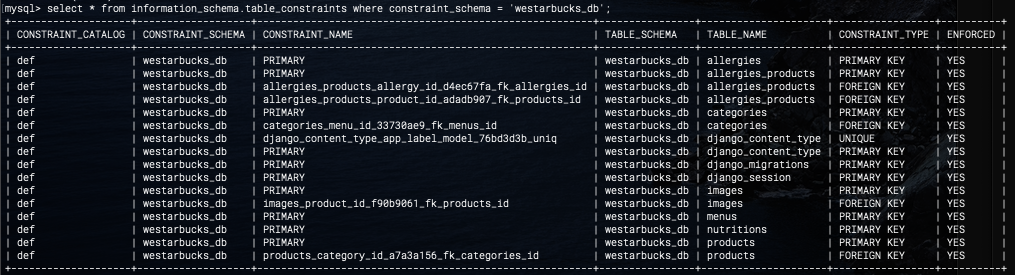
에러에서 나왔던 외래키 constraint ‘nutritions_ibfk_1’가 표에는 나오지 않는다.
그래도 지울 수 있을까 싶어서 아래 명령어를 쳐봤다.
ALTER TABLE nutritions DROP CONTRAINT nutritions_ibfk_1;
ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near ‘nutritions_ibfk_1’ at line 1
문법을 틀린 것 같은데 너무 멀리 온 것 같으니까 싹 밀고 마이그레이션을 다시 해야겠다.
READ
get은 쿼리셋을 1개, all(전부)과 filter는 쿼리셋을 많이 불러올 수 있고 쿼리셋에 담겨온 데이터들은 for문을 사용할 수 있다. filter는 쿼리셋을 0개 불러올 수도 있다.
>>> from products.models import Menu
>>> Menu.objects.all()
#<QuerySet [<Menu: 음료>, <Menu: 푸드>]
Menu.objects.get(name="음료")
#<Menu: 음료>
Menu.objects.filter(name="음료")
#<QuerySet [<Menu: 음료>]>
Menu.objects.filter(name="음료").values()
#<QuerySet [{'id': 1, 'name': '음료'}]>
values를 쓰면 제일 편하지만 처음에는 관계를 생각하면서 read하는걸 연습하기 위해서 다른 방법을 사용한다. - 위코드 멘토님
07.20 쿼리셋을 충분히 연습하지 않았어서 CRUD2를 할 때 복잡한 쿼리셋을 써야하면서 애를 먹었다. 뒤로 가니까 이런 식으로 사용하게 되는데 연습을 충분히 하지 않아서 그런지 잘 모르겠다. 다른 학우분들은 value+for문을 사용하고 있는데 보면서 물어보고 더 공부해봐야겠다.
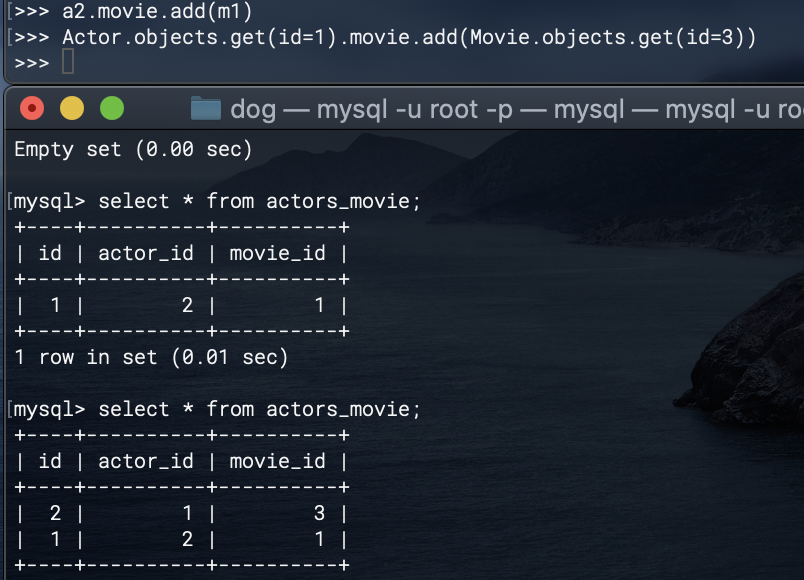
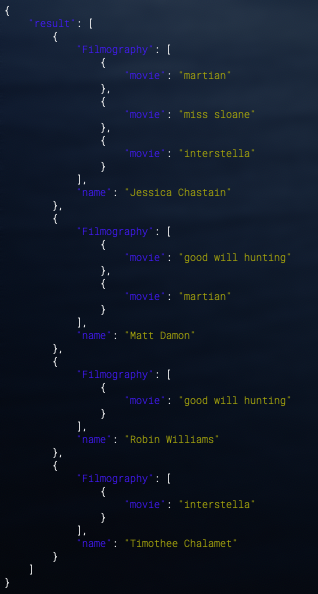
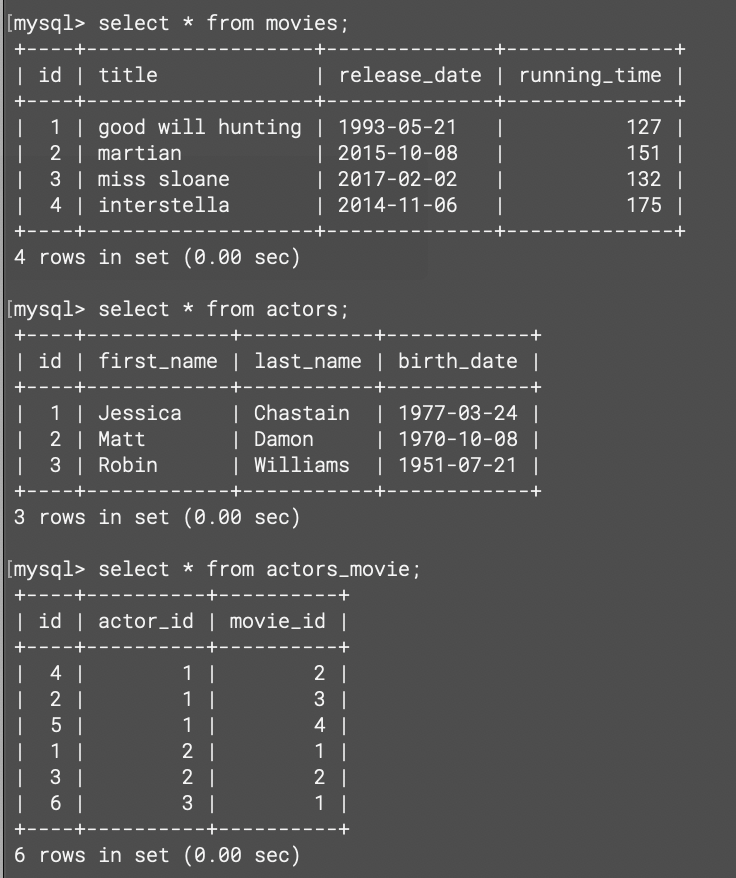
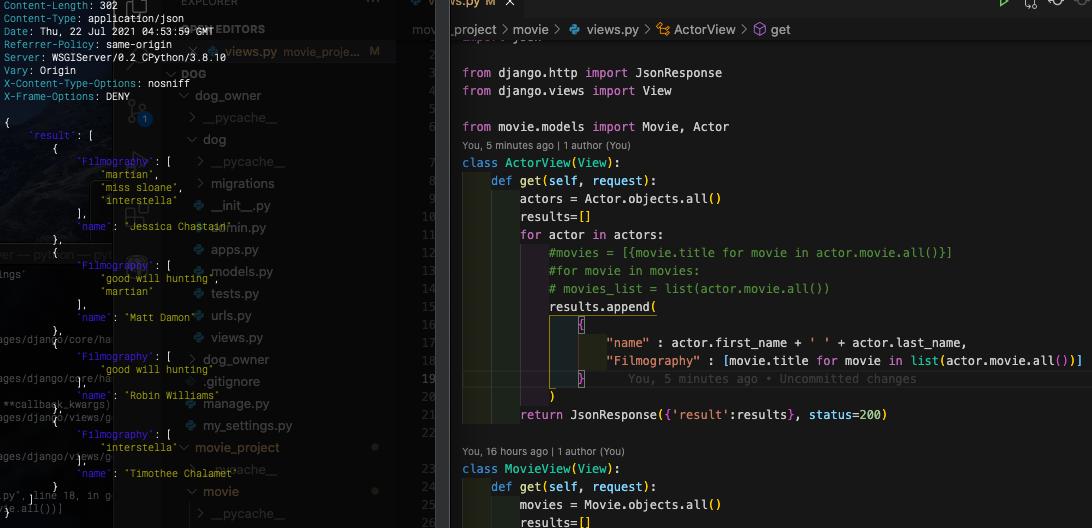
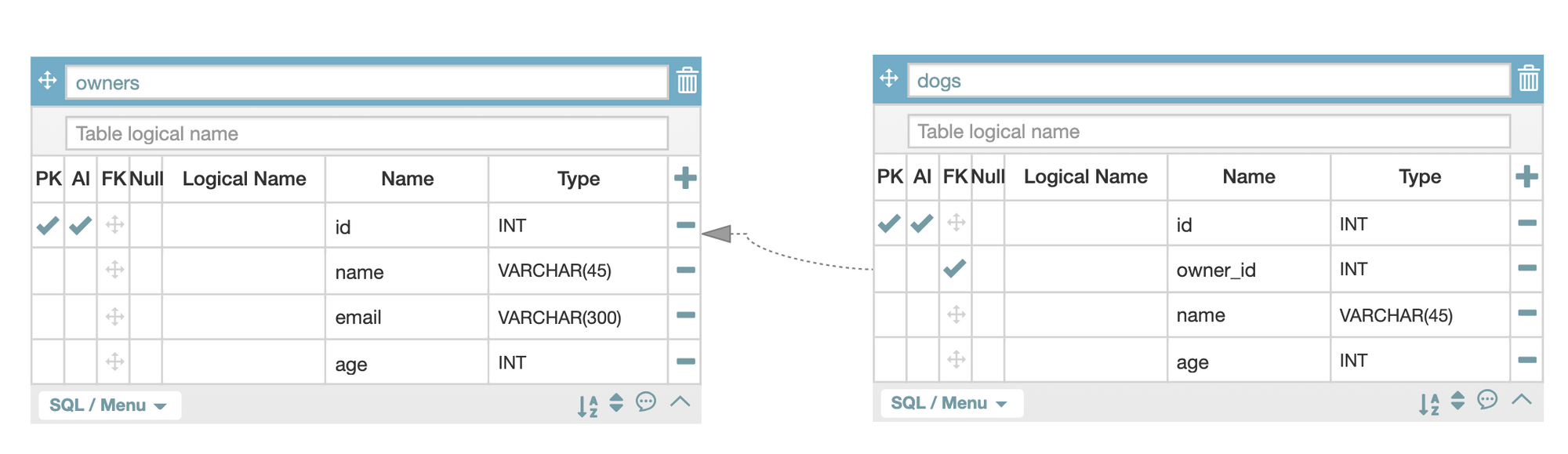
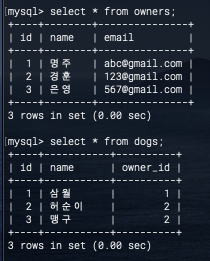
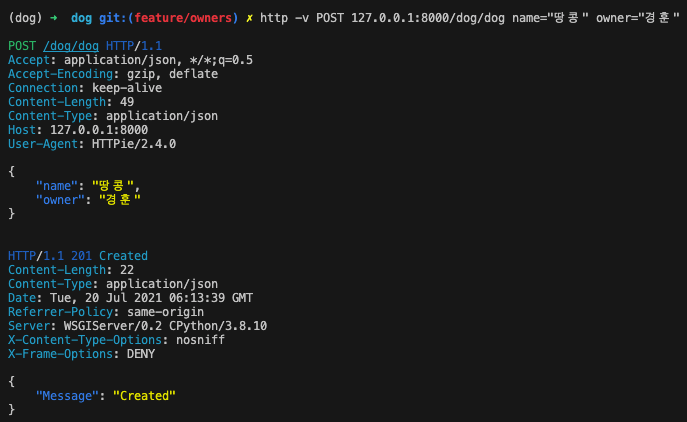
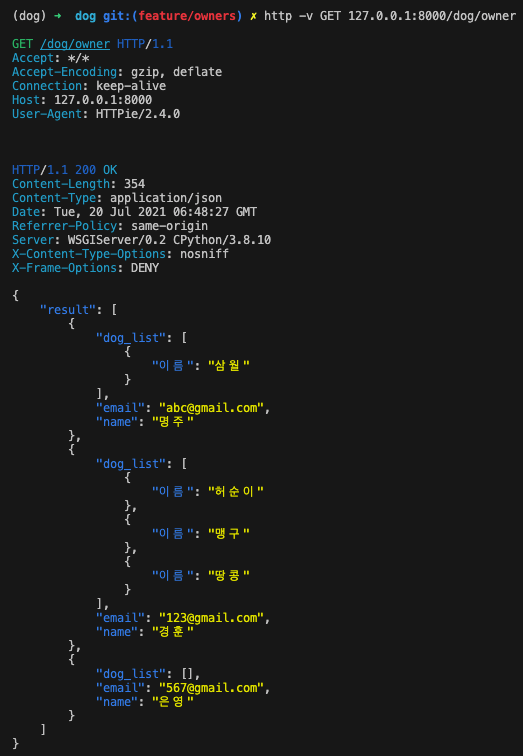
Owner.objects.get(name = data['owner'])
[{"이름":dog.name, "나이":dog.age} for dog in Dog.objects.filter(owner_id=owner.id)]
UPDATE
쿼리셋을 먼저 불러와야 update를 사용할 수 있다.
어떤 모델매쏘드가 어떤 데이터타입을 어떻게 반환하는지 알아야한다.