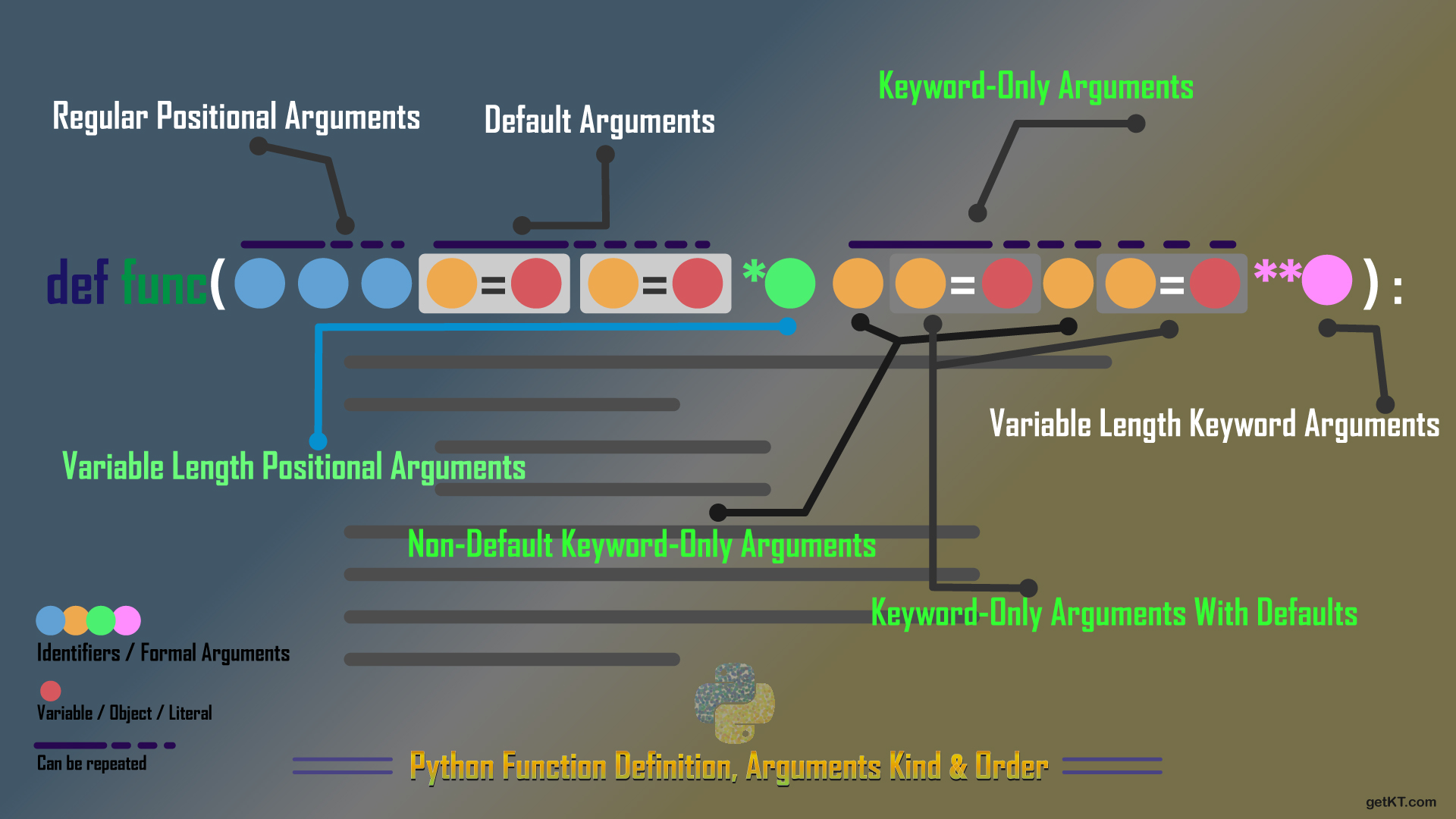
파이썬 - 데코레이터(decorator), 쿼리디버거
09 Jul 2021 | 기초 TILDecorator
Decorator를 한마디로 얘기하자면, 대상 함수를 wrapping 하고, 이 wrapping 된 함수의 앞 뒤에 추가적으로 꾸며질 구문 들을 정의해서 손쉽게 가능하게 해주는 것이다. 재사용, 분리를 위해서 함수를 따로 떼어서 원하는 곳에 붙여넣는 것이라고 생각하면 된다.
출처: https://bluese05.tistory.com/30 [ㅍㅍㅋㄷ]
함수의 내부를 수정하지 않고 기능에 변화를 주고 싶을 때 사용한다.
일반적으로 함수의 전처리나 후처리에 대한 필요가 있을때 사용을 한다.
또한 데코레이터를 이용해, 반복을 줄이고 메소드나 함수의 책임을 확장한다.
출처: https://hckcksrl.medium.com/
예를 들어서 로그인이 되었으면 아래 함수를 실행시키고 싶다고할 때
원하는 함수 위에 로그인 데코레이터를 넣어주면 된다. 마찬가지로 권한관리도 할 수 있다.
로그인 데코레이터 예시
어드민 데코레이터(권한관리) 예시
#뷰에서 아래와 같이 사용
@login_decorator
def ViewUserInfoView
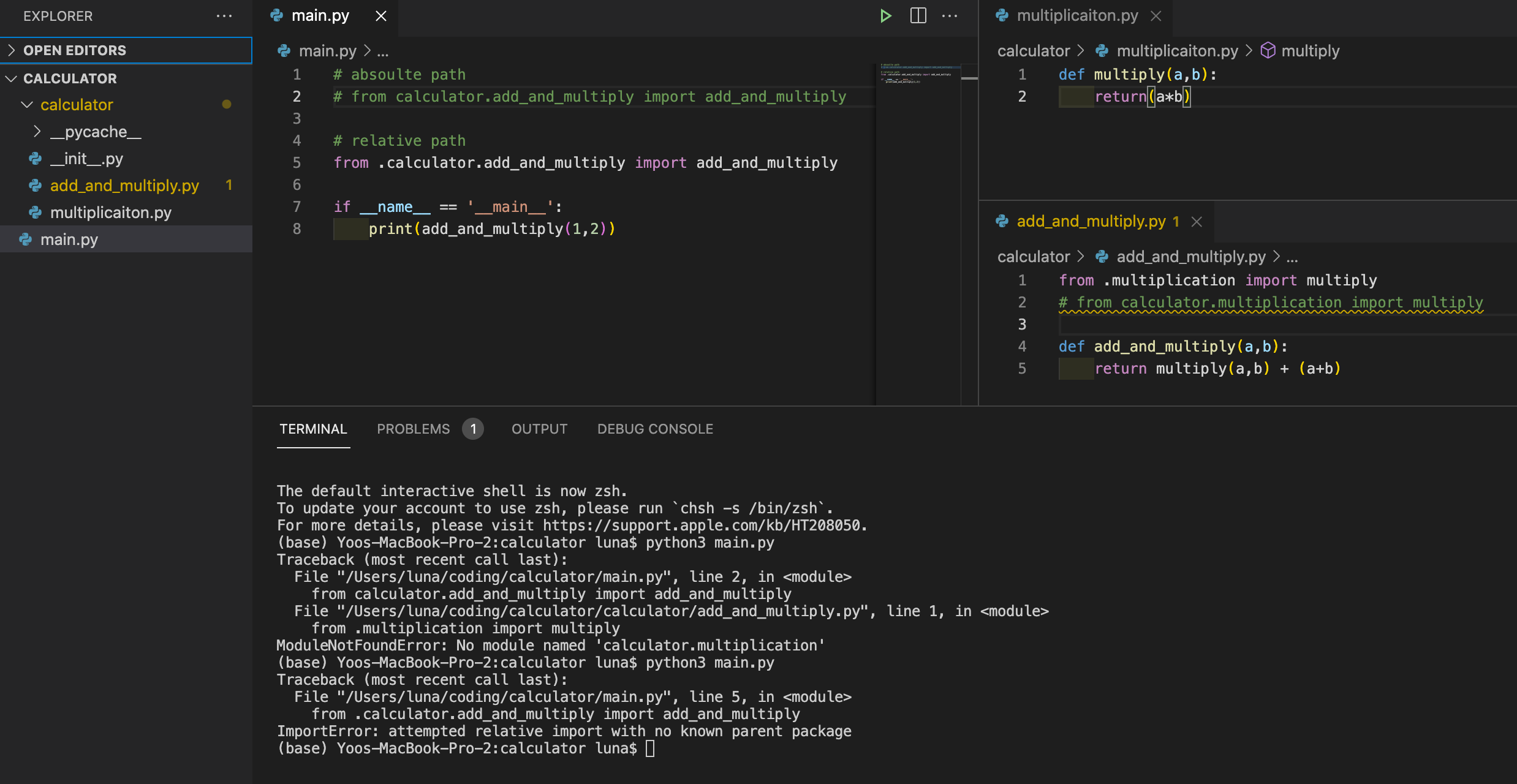
혹은 쿼리의 성능을 측정하고 싶을 때 쿼리 디버거 데코레이터를 만들어준 뒤에 함수 위에 넣어서 쿼리가 얼마나 걸리는지 측정할 수 있다.
#뷰에서 아래와 같이 사용
@query_debugger
def SearchView
#쿼리 디버거 함수 예시
import time
import functools
from django.db import connection, reset_queries
def query_debugger(func):
@functools.wraps(func)
def wrapper(*args, **kwargs):
reset_queries()
number_of_start_queries = len(connection.queries)
start = time.perf_counter()
result = func(*args, **kwargs)
end = time.perf_counter()
number_of_end_queries = len(connection.queries)
print(f"-------------------------------------------------------------------")
print(f"Function : {func.__name__}")
print(f"Number of Queries : {number_of_end_queries-number_of_start_queries}")
print(f"Finished in : {(end - start):.2f}s")
print(f"-------------------------------------------------------------------")
return result
return wrapper
예시1
def welcome_decorator(self):
def wrapper():
return self() + "welcome to WECODE!"
return wrapper
@welcome_decorator
def greeting():
return "Hello, "
print(greeting())
예시2
class Decorator:
def __init__(self, function):
self.function = function
def __call__(self, *args, **kwargs):
print('전처리')
print(self.function(*args, **kwargs))
print('후처리')
@Decorator
def example():
return '클래스'
#example() 실행
'''''''''
전처리
클래스
후처리
'''''''''
장고에서의 예시3
from django.http import HttpResponse
def only_admin(f):
def check(request, *args, **kwargs):
try:
if request.user.admin is not True:
return JsonResponse({
'status': False,
'message': 'admin permission is required'
})
except:
return JsonResponse({
'status': False,
'message': '\'sign in\' is required'
})
return f(request, *args, **kwargs)
return check
@only_admin
def add_target(request):
return HttpResponse('')